MaXiaoTiao
A Review on Multi-Label Learning Algorithms

A Review on Multi-Label Learning Algorithms
前置知识
单标签、多分类、多标签 、监督学习、 贝叶斯定理
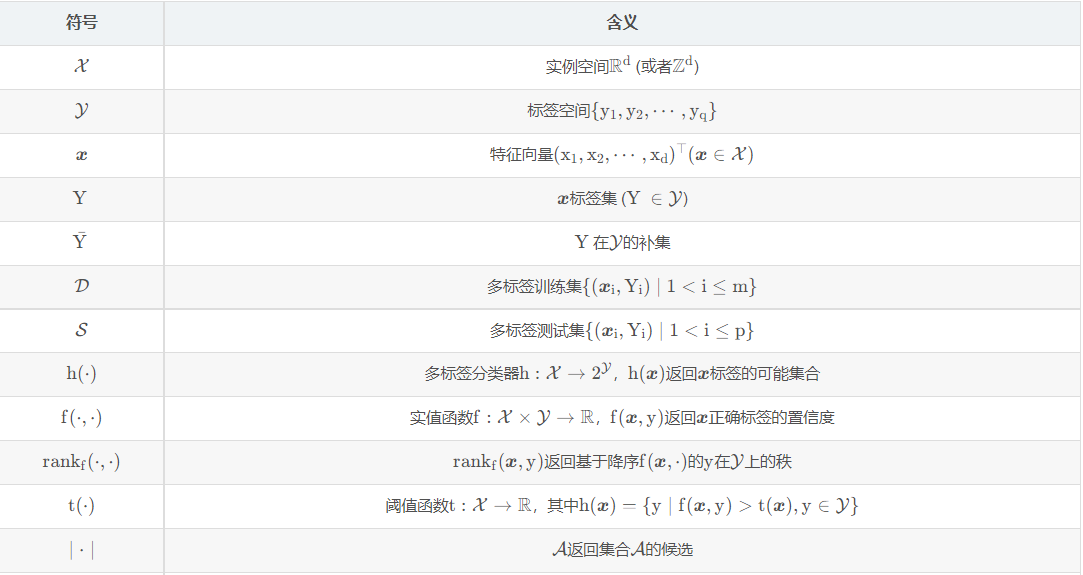
符号表

1 多标签
一个实例可能与多个类标签相关。比如一部电影,它可以与搞笑,热血,青春三个标签相关。
多标签学习通过训练基于多标签数据的模型,为不可见的实例预测相关的标签子集
多标签学习的核心问题之一是如何根据不同类别标签之间的相关性构建一个有效的学习模型来预测未知实例的标签集。
2多标签学习的概念
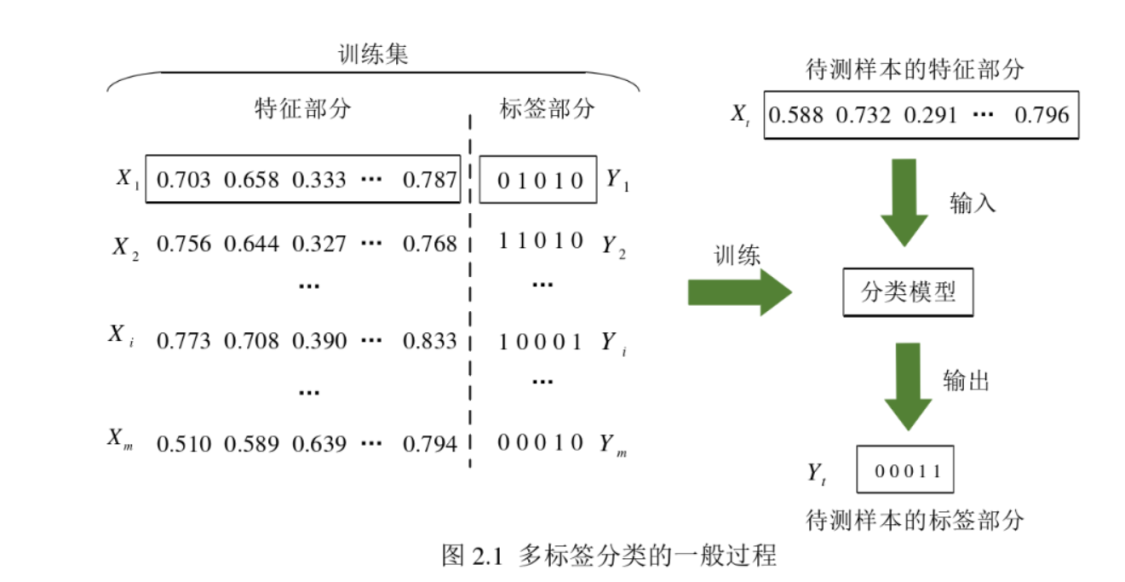
多标签数据由样本集合和标签集合组成。标签集合通常由{0,1}组成的矩阵,通常行表示样本,列表示标签。取值为1代表样本中包含该标签,0代表样本不包含该标签。
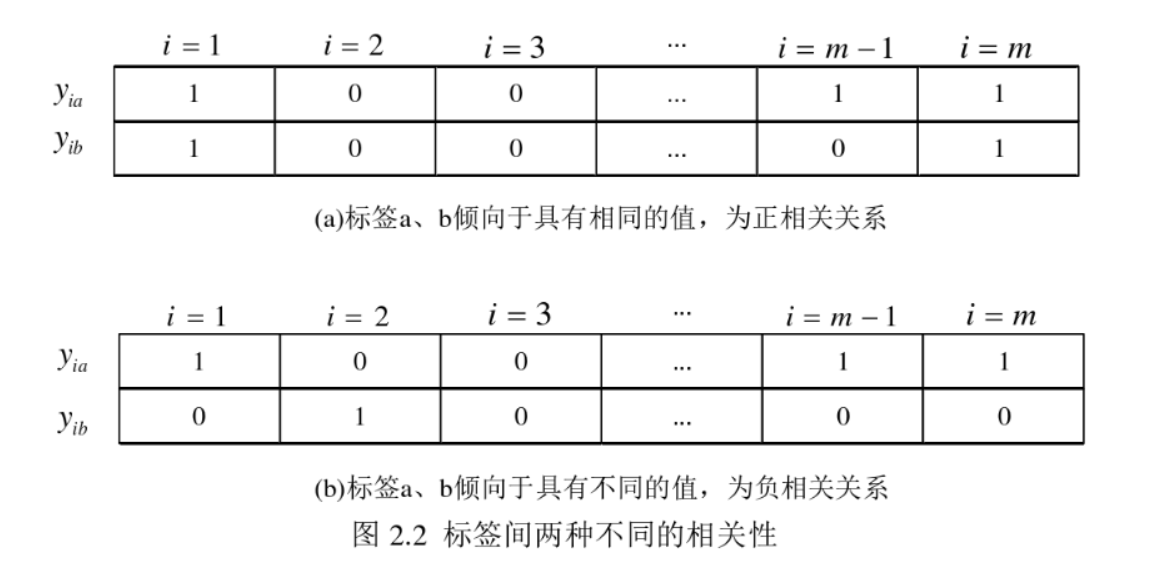
现实世界中,事物的类别属性往往不是孤立的,而是相互间存在一定的相关性。例如,一篇文章,同时属于“医疗”和“科技”类别的概率远大于同时属于“医疗”和“娱乐”类别的概率。从一定程度上来说,“医疗”和“科技”这两个类别标签就属于相关的,而且属于倾向于同时出现的“正相关”关系。与此相反,“医疗”和“娱乐”这两个标签一般可以认为是属于相互排斥的“负相关”关系。根据对多标签分类的定义,两种不同的相关关系一般以图2.2所示的形式出现。图中(a)表示m个样本中,标签a、b往往具有相同的值,则标签a、b间具有一定的正相关关系;(b)表示m个样本中,标签a、b通常具有不同的值,则标签a、b具有一定的负相关关系。除此之外,标签间相同(不同)的概率越大,则说明标签间正(负)相关关系越强。
3多标签算法的三种策略
多标签学习的主要难点在于输出空间的爆炸增长,比如20个标签,输出空间就有220220,为了应对指数复杂度的标签空间,需要挖掘标签之间的相关性。通过挖掘类标之间的关联性,可以有效的避免单独处理海量的潜在可能的标签集,而是转换成发掘标签之间的规律从而提升多标签学习能力。一个文档被标注为娱乐标签,它就不太可能和政治相关。有效的挖掘标签之间的相关性,是多标签学习成功的关键。根据对相关性挖掘的强弱,可以把多标签算法分为三类。
一阶策略:忽略和其它标签的相关性,比如把多标签分解成多个独立的二分类问题(简单高效,但由于标签并不关联,有效性低)。
二阶策略:考虑标签之间的成对关联,比如为相关标签和不相关标签排序。
高阶策略:考虑多个标签之间的关联,比如对每个标签考虑所有其它标签的影响(效果最优)。
4阈值校验
多标签学习通常返回一些实值函数f ( ⋅ , ⋅ ) ,在此设置下,为了获取实例x的可能标签,f ( x , y ) 在每个标签上的输出就应根据阈值函数t ( x ) 进行校验。有了目标函数之后,还需要一个合适的阈值来决定得到当前目标函数的输出值的该标签是否应该与样本相关联或者是否为该标签。
5评价指标
基于样本的评价指标(先对单个样本评估表现,然后对多个样本取平均)
基于标签的评价指标(先考虑单个标签在所有样本上的表现,然后对多个标签取平均)
Example-based metrics:
评价每个单独样本集上学习系统的表现,返回一个测试集之间的mean value.
Subset Accuracy:
评估正确分类样本的分数,预测的样本集和真实的样本集完全一样才算正确,也就是预测标签类别与实值标签类别是否相符。其中p表示测试集的样本大小,1{π}表示π为真时返回1,否则返回0。
Hamming loss:
衡量的是错分的标签比例,正确标签没有被预测以及错误标签被预测的标签占比,其中Δ表示两个集合的对称差,返回只在其中一个集合出现的那些值。
海明损失可以用来评估一个样本被错分多少次,例如,一个样本不属于标签A但是被错分成标签A,或者是,一个样本属于标签A,但是没有被预测为标签A。
也可以说,用海明损失来计算分类器预测出的结果序列与结果序列之间的数值上的距离。海明损失越小,预测结果越好。
One-error:
错误率可以用来评估在输出结果中排序第一的标签并不属于实际标签集中的概率。相当于单标签分类问题中的评价指标error。1-错误率越小,预测结果越好。
g(x)=0,x为假;g(x)=1,x为真
Ranking loss
排序损失表示有多少不相关的标签排序高于相关的标签。排序损失用来表示在结果排序中,不属于相关标签集中的项目被排在了属于相关标签集中项目的概率的平均。排序损失越小,预测结果越好。
Average precision,AVP
平均精度在所有的预测结果排序中,排序排在相关标签集的标签前面,且属于相关标签集的概率,该指标反映了分类标签的平均精确度。这个指标最初用于信息检索(IR)系统,用来评估检索的文本排序性能。平均精度越大,预测效果越好。
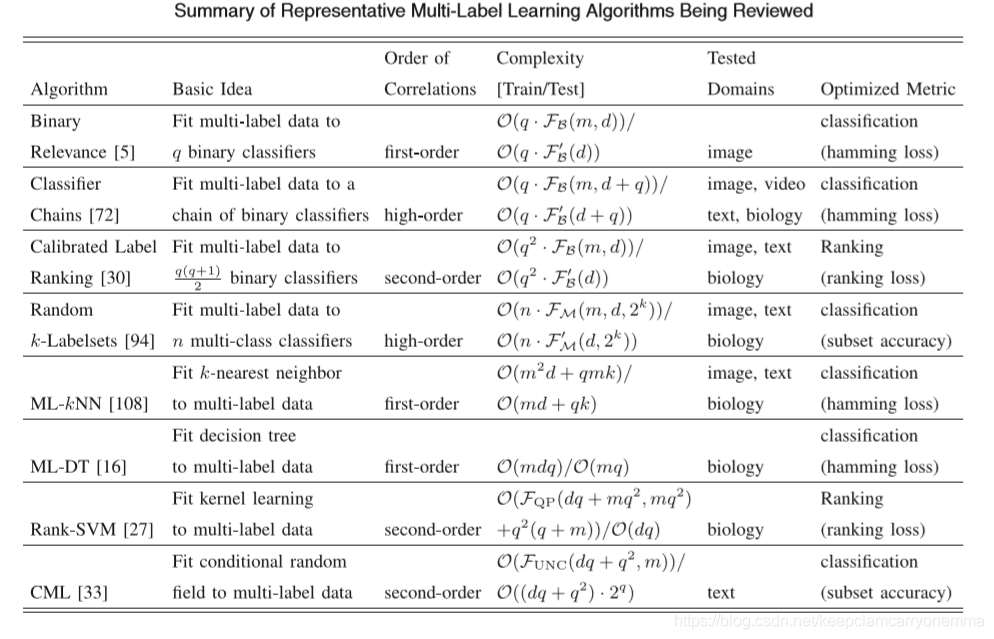
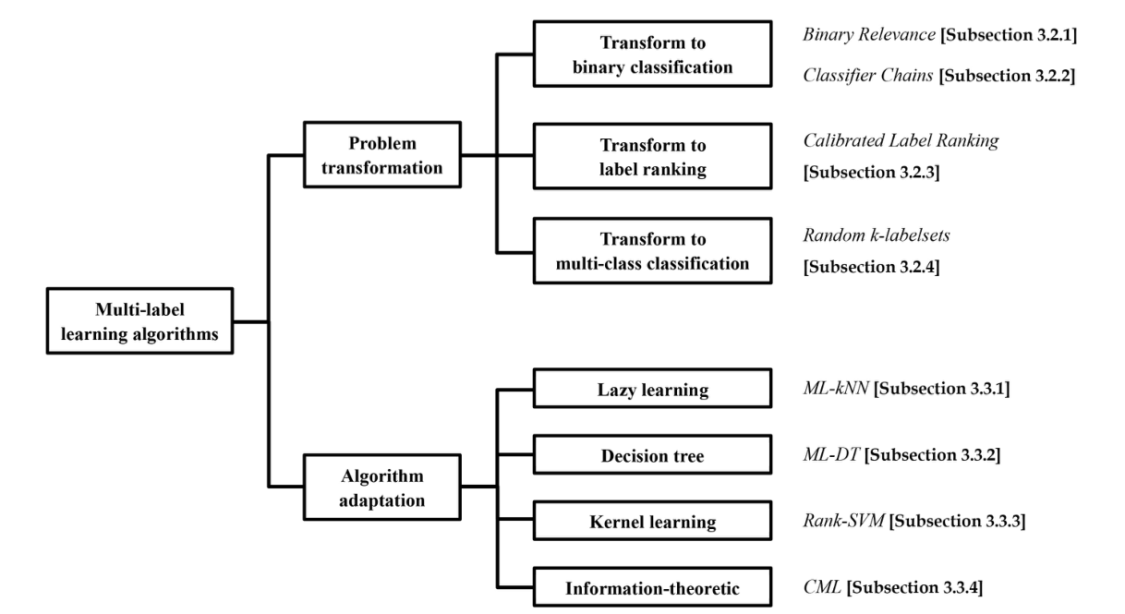
6多标签的学习算法
多标签分类学习算法可分为两类:
问题转换的方法:把多标签问题转为其它学习场景。这类算法通过将多标签学习问题转化为其他成熟的学习场景来处理多标签学习问题。 代表性的算法包括一阶方法、二阶相关和高阶方法分类器链,一阶方法将多标签学习任务转换为二元分类任务,二阶方法校准标签排序将多标签学习任务转换为 标签排序任务和高阶方法将多标签学习任务转化为多类分类任务的随机k标签集。比如转为二分类,标签排序,多分类
算法适应的方法:通过改编流行的学习算法去直接处理多标签数据。这类算法通过适应流行的学习技术直接处理多标签数据来处理多标签学习问题。具有代表性的算法包括一阶MLKNN自适应延迟学习技术,一阶ML-DT自适应决策树技术,二阶Rank-SVM自适应核心技术,以及二阶CML自适应信息理论技术。比如改编懒学习,决策树,核技巧。
问题变换方法的关键原理是将数据拟合到算法中,
算法自适应方法的关键原则是将算法适用于数据。
6.1 Binary Relevance算法
BR算法将原始多标签数据集按标签个数划分为若干个单标签数据集。在每个单标签数据集内用单标签分类算法进行分类,最后将获得的标签结果拼接得到多标签分类的结果多标签数据集分解为多个独立的基于二元分类的单标签数据集。
把多个标签分离开来,对于q个标签,建立q个数据集和q个二分类器来进行预测。这是最简单最直接的方法,是其它先进的多标签算法的基石。没有考虑标签之间的关联性,是一个一阶策略
6.2 Classifier Chains算法
首先按特定的顺序(这个顺序是自己决定的)对q个标签排个序,得到yτ(1)≻yτ(2)≻…≻yτ(q)。当预测序列中第j个标签时,需要将序列在之前的标签所预测的结果作为特征加入到训练集中构成新的训练集,然后针对构建二元分类器:
第j个标签构建的二分类数据集中,xixi会concat上前j-1个标签值。以这样链式的方法构建q个数据集,训练q个分类器。在预测阶段,由于第j个分类器需要用到前j-1个分类器预测出的标签集,所以需要顺序调用这q个分类器来预测。
Classifier Chains的核心思想是将多标签分类问题进行分解,将其转换成为一个二元分类器链的形式,其中后链的二元分类器的构建是在前面分类器预测结果的基础上的
6.3 Calibrated Label Ranking算法
CLR(Calibrated Label Ranking)是一种问题转换和二阶标签相关性算法。
该算法思想主要是利用两两标签互相比较来实现标签有序的形式。
当需要预测一个未知样本的标签集合时,clr算法首先将其与之前训练的(n*(m-1)/2个二分类器进行预测标签统计,其次利用投票算法得到该未知样本对于不同标签的综合投票结果,最后再对所得的综合投票结果实施排序。
6.4 Random k-Labelsets算法
RAKEL(Random K-Labelsets)是一种问题转换和高阶标签相关性算法。
该算法的主要思想是基于LP(Label Powerset)算法,其中任意的基分类器分别对应标签集合中一个任意随机标签子集。
LP属于一种问题转换算法。其算法的主要思想是将标签集合的标签编码成不同的新标签子集,而这些新的标签具有相关性。例如,标签集合的标签数为L个,那么能够组合成的标签数为L2。然而,LP存在一些缺点:(1)如果原始标签集数量很大,那么组合成的新标签数量非常庞大,容易导致训练分类器的时间复杂度变高;(2)无法进行未知标签类别的预测;(3)如果原始标签集的数量特别大,那么容易造成新的类别不平衡。
6.5 Multi-Label k-Nearest Neighbor(ML-KNN)k 近邻算法
k NN算法是最简单分类算法之一,其中约定俗成用“k”来代表近邻数。kNN算法的核心思想是基于距离或其他相似度在特征空间中找到距离待分类样本最近的k个样本;这k个样本则为最近邻,k个最近邻的大多数所在的类,即为待分类样本的类别。
k近邻(KNN)算法的思想是给出一个样本集合和一个合适的距离度量方式,对任意的一个测试样本,找到离它最近的k个样本,根据这k个样本的类别统计信息决定此测试样本的类别归属问题。k近邻算法,k的取值会影响分类器性能,即k值偏小体现样本的特点,反之则会增加噪声。因为KNN算法是一种懒惰学习算法,在对样本进行分类时直接进行分类计算。KNN的优点是算法简单,准确度高;
缺点是计算复杂度较高,易受k近邻样本的影响
ML-KNN是在KNN算法的基础上,提出的一种懒惰的多标签学习算法。首先通过KNN算法得到样本最接近的K个邻近样本,然后根据K个邻近样本的标签,统计属于某一标签的邻近样本个数,最后利用最大后验概率原则(MAP)决定测试样本含有的标签集合。ML-KNN算法对于多标签数据集具有良好的分类性能,但ML-KNN算法未充分考察样本多个标记之间相关性。
6.6 Multi-Label Decision Tree(ML-DT)决策树算法
决策树(Decision Tree)基于树结构进行分类判决,是一种应用广泛的机器学习算法。一般情况下,学习的目的是构造出处理未知样本性能优秀的决策树。决策树的生成是一个递归的过程,决策树依靠对源数据库的分割来完成对数据集的分类,采用递归式的对树进行修剪。
计算思想如下:首先计算每个特征的信息增益,挑选增益最大的特征来划分样本为左右子集,递归下去,直到满足停止条件,完成决策树的构建。对新的测试样本,沿根节点遍历一条路径到叶子节点,计算叶子节点样本子集中每个标签为0和1的概率,概率超过0.5则表示含有该标签。当遍历所有路径到底不同的叶节点之后,则可判断涵盖的所有标签信息。
6.7 Ranking Support Vector Machine(Rank-SVM) 支持向量机算法
SVM算法是一种典型的线性分类器,目标是得到最大边距超平面,将不同类别的样本分隔开来。
Rank-SVM基于SVM进行改造,针对标签之间的联系,采用将样本的相关标签与无关标签两两配对分隔在超平面两边的方法,完成多标签分类任务。
6.8 Collective Multi-Label Classifier(CML)算法
该算法的基本思想是适应最大熵原理处理多标签数据,其中标签之间的相关性被进行编码,成为所得到的结果分布必须满足的约束。从统计学上讲,多标签学习本质上就是通过学习得到样本和标签空间的联合概率分布。最大信息熵则是假定若样本于标签空间最优分布,则样本与标签集对应的信息熵最大。在该算法中考虑每个标签对之间的关系,故是一个二阶算法。相比Rank-SVM算法具有更强的普适性,但相应的计算更为复杂计算成本更加高。