
MaXiaoTiao
BERT 的结构:强大的特征提取能力
BERT 的结构:强大的特征提取能力
如下图所示,我们来看看 ELMo、GPT 和 BERT 三者的区别
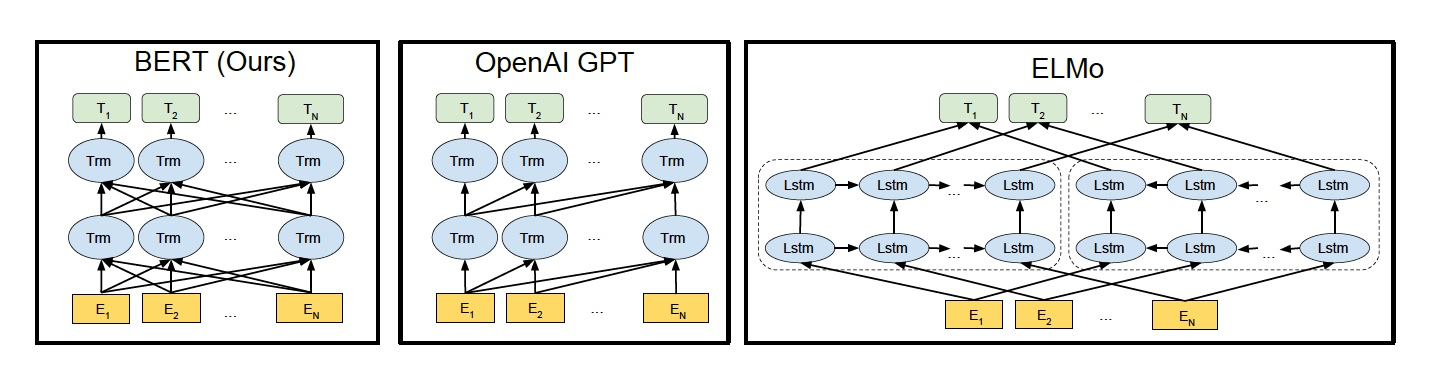
ELMo 使用自左向右编码和自右向左编码的两个 LSTM 网络,分别以 P(wi|w1,⋯,wi−1)P(wi|w1,⋯,wi−1) 和 P(wi|wi+1,⋯,wn)P(wi|wi+1,⋯,wn) 为目标函数独立训练,将训练得到的特征向量以拼接的形式实现双向编码,本质上还是单向编码,只不过是两个方向上的单向编码的拼接而成的双向编码。
GPT 使用 Transformer Decoder 作为 Transformer Block,以 P(wi|w1,⋯,wi−1)P(wi|w1,⋯,wi−1) 为目标函数进行训练,用 Transformer Block 取代 LSTM 作为特征提取器,实现了单向编码,是一个标准的预训练语言模型,即使用 Fine-Tuning 模式解决下游任务。
BERT 也是一个标准的预训练语言模型,它以 P(wi|w1,⋯,wi−1,wi+1,⋯,wn)P(wi|w1,⋯,wi−1,wi+1,⋯,wn) 为目标函数进行训练,BERT 使用的编码器属于双向编码器。
BERT 和 ELMo 的区别在于使用 Transformer Block 作为特征提取器,加强了语义特征提取的能力;
BERT 和 GPT 的区别在于使用 Transformer Encoder 作为 Transformer Block,并且将 GPT 的单向编码改成双向编码,也就是说 BERT 舍弃了文本生成能力,换来了更强的语义理解能力。
BERT 的模型结构如下图所示:
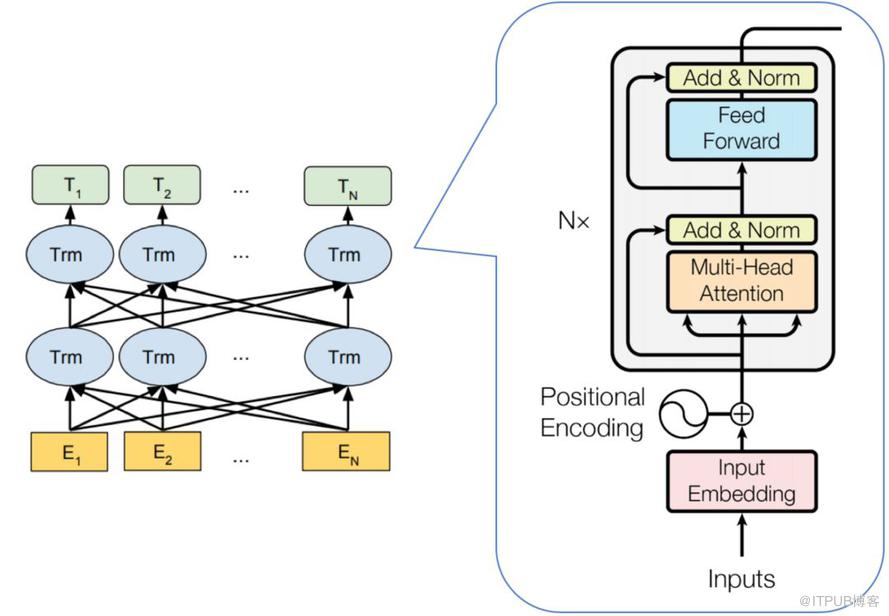
从上图可以发现,BERT 的模型结构其实就是 Transformer Encoder 模块的堆叠。在模型参数选择上,论文给出了两套大小不一致的模型。
BERTBASEBERTBASE :L = 12,H = 768,A = 12,总参数量为 1.1 亿
BERTLARGEBERTLARGE:L = 24,H = 1024,A = 16,总参数量为 3.4 亿
其中 L 代表 Transformer Block 的层数;H 代表特征向量的维数(此处默认 Feed Forward 层中的中间隐层的维数为 4H);A 表示 Self-Attention 的头数,使用这三个参数基本可以定义 BERT的量级。
BERT 参数量级的计算公式:
词向量参数+12∗(Multi−Heads参数+全连接层参数+layernorm参数)=(30522+512+2)∗768+768∗2+12∗(768∗768/12∗3∗12+768∗768+768∗3072∗2+768∗2∗2)=108808704.0≈110M