
MaXiaoTiao
BERT 之输入表示
BERT 之输入表示
BERT的输入序列构造如下:
[CLS] Token: 输入序列的开始是一个特殊的分类token([CLS]),其最终的隐藏状态被用作分类任务的聚合序列表示。
Token Embeddings: 接下来是句子中每个token的WordPiece tokenization结果。
[SEP] Token: 两个句子之间通过一个特殊的分隔token([SEP])进行分隔。
Padding: 如果输入序列的长度小于BERT的最大序列长度(通常是512),则使用特殊的填充token([PAD])进行填充。
Attention Mask: 为了避免在padding token上计算注意力,BERT使用一个注意力掩码,该掩码在padding token的位置上为0,在有效token的位置上为1。
Segment IDs: 每个token都分配一个段ID,以指示它属于第一个句子还是第二个句子。
4. 实例
假设我们有两个句子 “Hello, how are you?” 和 “I am fine, thank you.”,BERT的输入序列可能如下所示:
复制
[CLS] Hello, how are you? [SEP] I am fine, thank you. [SEP]
对应的嵌入表示将结合以下三个部分:
Token Embeddings for each token.
Segment Embeddings: 例如,第一个句子的所有token可能都有一个段嵌入向量表示为0,而第二个句子的所有token的段嵌入向量表示为1。
Positional Embeddings: 根据每个token在序列中的位置分配。
5. 输入表示的限制
BERT的最大序列长度通常是512个token。如果输入文本超过这个长度,需要截断或分割文本。在实际应用中,这可能需要一些策略来确保信息的完整性。
通过这种方式,BERT能够将文本转换为具有丰富语义信息的固定大小的向量表示,这些表示随后可以被Transformer架构有效地处理。
BERT 在预训练阶段使用了前文所述的两种训练方法,在真实训练中一般是两种方法混合使用。
由于 BERT 通过 Transformer 模型堆叠而成,所以 BERT 的输入需要两套 Embedding 操作:
一套为 One-hot 词表映射编码(对应下图的 Token Embeddings);
另一套为位置编码(对应下图的 Position Embeddings),不同于 Transformer 的位置编码用三角函数表示,BERT 的位置编码将在预训练过程中训练得到(训练思想类似于Word Embedding 的 Q 矩阵)
由于在 MLM 的训练过程中,存在单句输入和双句输入的情况,因此 BERT 还需要一套区分输入语句的分割编码(对应下图的 Segment Embeddings),BERT 的分割编码也将在预训练过程中训练得到
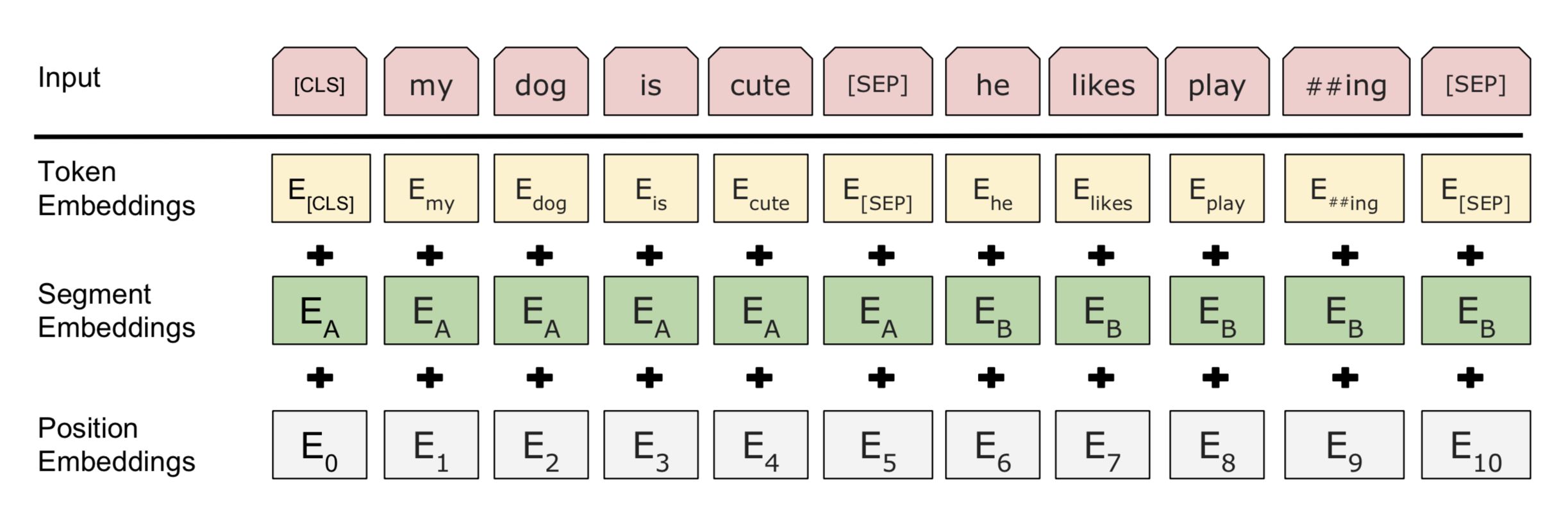
对于分割编码,Segment Embeddings 层只有两种向量表示。前一个向量是把 0 赋给第一个句子中的各个 token,后一个向量是把 1 赋给第二个句子中的各个 token ;如果输入仅仅只有一个句子,那么它的 segment embedding 就是全 0,下面我们简单举个例子描述下:
[CLS]I like dogs[SEP]I like cats[SEP] 对应编码 0 0 0 0 0 1 1 1 1
[SEP]I Iike dogs and cats[SEP] 对应编码 0 0 0 0 0 0 0
