
MaXiaoTiao
多标签阶段性论文总结

多标签算法学习综述
摘要:多标签学习作为机器学习领域的一个重要研究方向,旨在解决将实例分配给多个标签的任务。随着对多标签学习的广泛关注,研究人员提出了各种各样的方法和算法。然而,目前文献中对这些方法进行广泛的实验比较和评估的研究还相对较少。本研究针对多标签学习方法进行了广泛的实验评估,并采用了不同类型的基本机器学习算法和多个评估措施来评估这些方法的性能。同时,我们还使用了来自不同应用领域的多个数据集进行了综合评估。
本研究对多标签学习方法进行了广泛的实验评估,并提供了对这些方法性能和效率的全面分析。我们的研究结果对多标签学习领域的研究和实践具有重要意义,并为选择适当的方法和算法提供了指导。未来的研究可以进一步扩展比较的范围,并考虑其他评估措施,以进一步提高多标签学习的性能和效率。
关键字:多标签;机器学习;评估措施;
An overview of multi-label algorithm learning
Abstract: Multi-label learning, as an important research direction in the field of machine learning, aims to solve the task of assigning multiple labels to instances. With the widespread attention to multi-label learning, researchers have proposed various methods and algorithms. However, there is still a lack of extensive experimental comparisons and evaluations of these methods in the literature. In this study, we conducted extensive experimental evaluations of multi-label learning methods and evaluated their performance using different types of basic machine learning algorithms and multiple evaluation measures. Additionally, we conducted comprehensive evaluations using multiple datasets from different application domains.
In summary, this study provides extensive experimental evaluations of multi-label learning methods and offers a comprehensive analysis of their performance and efficiency. Our research findings are of great significance to the research and practice in the field of multi-label learning and provide guidance for selecting appropriate methods and algorithms. Future research can further expand the scope of comparisons and consider additional evaluation measures to further enhance the performance and efficiency of multi-label learning.
KEYWORDS: multi-label; machine learning; evaluation measures.
1.引言
在机器学习中,传统监督学习是最广泛研究和应用的学习框架。在传统监督学习中,每个对象通过一个示例(通常是属性向量)在输入空间中描述其特征,并与表示该对象语义信息的类别标签相关联,在输出空间中形成一个样本。通过使用一个较大的训练集,学习系统通过某种学习算法学习输入空间与输出空间之间的映射关系,从而可以对未见示例进行类别标记的预测。这一框架在具有明确且唯一语义的对象上取得了巨大成功。
然而,在真实世界中,对象往往不仅具有唯一的语义,还可能具有多义性。例如,对于图1(a)中关于南非世界杯的新闻报道,它既可以被认为属于“体育”类别,也可以被认为属于“非洲”类别,甚至可能还涉及到与“经济”相关的内容;同样,对于图1(b)中的图像,它既可以被认为属于“日落”类别,也可以被认为属于“云”、“树木”或者“乡村”类别。这种多义性的例子还有很多,例如基因可能具有多种功能标记,一首乐曲可能传达多种信息,等等。

图 1 多义性对象的两个例子
传统监督学习框架在处理多义性对象时面临困难,因为这些对象不再具有唯一的语义。为了直观地反映多义性对象所具有的多种语义信息,多标签学习框架应运而生。在多标签学习框架下,每个对象由一个示例描述,该示例具有多个类别标签,而不仅仅是一个。学习的目标是为未见示例赋予所有适当的类别标签。最初,多标签学习的研究主要集中在处理文本分类中的多义性问题。随着近十年来的发展,多标签学习技术已经在多媒体内容自动标注、生物信息学、Web挖掘、信息检索、个性化推荐等领域得到广泛应用。
近年来,关于多标签学习的论文数量不断增加。据笔者不完全统计,近四年来在国际一流机器学习会议如ICML、NIPS、ECML/PKDD、KDD、ICDM、IJCAI和AAAI上,含有关键词"多标签(multi-label/multilabel)"的论文超过了30篇。此外,近两年的ECML/PKDD'09和ICML/COLT'10均设有关于"Learning from Multi-Label Data"的专题研讨会。多标签学习的研究进展也受到国际机器学习期刊《Machine Learning》的关注,该期刊将很快推出一个专题专辑,重点介绍多标签学习的相关内容[2]。
综上所述,多标签学习对于处理多义性对象的学习建模具有重要意义,已经成为国际机器学习界的一个研究热点。本章将对多标签学习的研究现状进行介绍,包括定义和面临的主要问题,介绍多标签学习的性能评价指标,并重点介绍几种代表性的多标签学习算法。
2. 研究目的和研究意义
图2显示了机器学习社区对多标签学习任务的兴趣日益浓厚,并呈现了一个增加的趋势。这表明出现了新的多标签问题和方法。由于存在大量的问题、方法和数据集,无论是新手还是经验丰富的从业者都很难为他们的问题选择最合适的方法。此外,在提出新方法时,也存在不清楚应该使用什么样的基准基线的问题。因此,对现有方法和问题进行综述和改进是推动该研究领域进一步发展的必要条件。
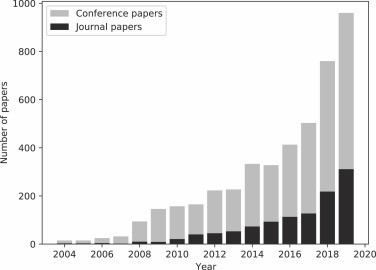
图 2 机器学习社区对多标签学习任务趋势图
在过去的研究中,已经尝试解决多标签学习中选择最合适的方法和评估基准的问题。然而,这些研究在方法和数据集的范围方面存在限制,缺乏全面的实证研究。以下是几个重要的研究:
Madjarov等人(2012)进行了第一个全面的实证研究,分析了12种多标签学习方法在11个基准问题和16个评估标准上的性能。他们的研究提供了指导从业人员选择多标签学习方法的结论,但随着新方法和问题的出现,该研究已经过时。
Gibaja和Ventura(2015)提供了关于多标签学习任务的详细信息,包括方法、评估标准、数据预处理技术和问题的组织。然而,他们缺乏对不同数据集上方法的全面实证评估。
Zhang和Zhou(2014)提供了八种多标签学习方法的理论论文和伪代码,并详细讨论了这些方法如何处理多标签学习任务的细节。
Herrera等人(2016)的研究是一本关于多标签学习的书,通过实证比较广泛概述了现有方法。然而,它缺乏与之前一些研究相比的相对实证性。
最近的研究由Moyano等人(2018)进行,他们在与Madjarov等人(2012)类似的实验设置中进行了分析,并扩展到多标签学习方法集成。他们发现集成学习方法在性能方面优于单模型学习方法,但构建集成模型需要更多计算时间。
总之,虽然有一些关于多标签学习方法和评估基准的研究,但仍缺乏全面的实证研究,特别是随着新方法和数据集的出现。这需要进一步的研究来提供方法的全面调查和评估基准的发展。
3 多标签分类的任务
3.1. 多标签分类数据集
在本研究中,考虑的多标签分类(MLC)数据集主要来自生物学、文本和多媒体等应用领域。生物学数据集通常包含描述性变量表示的蛋白质,并且目标是预测基因功能或亚细胞定位等属性。文本领域的数据集通常涉及对新闻文档进行主题分类,但也可以预测医疗报告中的心血管状态或评论中的推荐标签等目标。多媒体领域的数据集可以分为图像分类(通常是给定图像中的场景)和音频内容分类(如流派、情感)等两类。
除了这些领域外,还可以使用来自医学和化学等其他领域的数据集。医学领域的数据集可以根据患者症状或重要测量值(如血压)的状态对疾病进行分类。化学领域的数据集涉及对观察对象中的化学浓度进行分类。这些多样的数据集反映了多标签分类任务的广泛应用潜力。有关使用的数据集的详细统计数据可以在附录A的表A.1中找到。
多标签数据集通过五个基本元特征描述:实例/示例数、特征数、标签数、标签基数和标签密度。这些元特征在数据集中的分布可以在图2中看到。训练示例的数量范围从174到17190不等。示例的数量范围广泛,可以用来评估MLC方法对输入数据丰富度的鲁棒性。
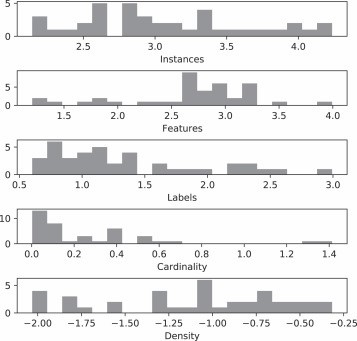
图 3 多标签数据集特征描述
此外,数据集的特征数量范围从19到9844不等。主要特征的数量在300到2000之间。在大多数数据集中,特征要么只包含数字属性,要么只包含名义属性,很少混合了这两种类型。标签数量是MLC分类任务的一个关键属性,其范围从4到374,大多数情况下,标签数量在4到53之间。
其他与数据集相关的讨论包括标签基数和标签密度。标签基数是衡量每个示例上标签分布的度量,它表示平均每个示例关联的标签数量。在大多数数据集中,标签基数小于1.5,表明这些数据集平均每个示例关联一个标签。大多数情况下,每个示例分配的标签数量不超过三个。少数例外是数据集"delicious"和"cal500",它们平均每个示例分配约19个和26个标签。标签密度是标签频率的度量,计算方法是标签基数除以标签数。在图中,标签密度以对数刻度表示。
3.2. 任务描述
多标签分类的任务可以看作是结构化输出预测的实例化形式。目标是为每个示例定义两组标签:相关标签集和不相关标签集。根据Madjarov等人的定义,多标签分类的任务可以表示为:
给定:
实例空间:由原始数据类型的值元组组成,表示描述性属性的数量为d。
标签空间:一组可能的标签,标签数量为L。
一组示例:每个示例由示例空间和标签空间的子集组成,即(x_i, Y_i),其中i表示示例的数量为N。
质量标准:奖励具有高预测性能和低复杂性的模型。
找到:一个函数f,使得f最大化目标函数值,该目标函数表示为:
目标函数 = 准确性(Y_i, f(x_i)) - 复杂性(f)
其中,准确性衡量模型预测与真实标签的一致性,复杂性衡量模型的复杂程度。
4. 多标签分类方法的分类
多标签分类方法是为了解决多标签分类任务而开发的特定机器学习算法。这些方法的目标是同时预测每个示例的多个标签,而不仅仅是单个标签。
4.1. 问题转换方法
问题转换方法将多标签数据集转换为一个或多个单标签数据集,并使用单目标机器学习方法构建一个或多个单目标模型来处理这些数据集。在预测阶段,需要调用所有模型来预测测试样本。以下是几种常见的问题转换方法:
4.1.1. 二元关联法(Binary Relevance,BR)
二元关联法是最简单和最常用的问题转换方法之一。它将多标签分类问题转化为L个独立的二分类问题,每个问题对应一个标签。对于每个标签,我们训练一个独立的二分类分类器,然后在预测阶段使用这些分类器进行预测。BR方法忽略了标签之间的相关性,即每个标签的预测是相互独立的。尽管BR方法简单,但它在处理大规模多标签数据集时具有较好的可扩展性和效率。
4.1.2. 分类器链法(Classifier Chains,CC)
分类器链法是另一种常见的问题转换方法,它考虑了标签之间的相关性。CC方法通过将标签序列化,每个标签的预测都考虑了前面标签的预测结果。具体来说,对于第i个标签,输入实例的特征向量除了原始特征外,还包括前面i-1个标签的预测结果作为额外的输入。这样可以利用标签之间的相关性来提高预测性能。例如,在文本分类中,通过将已预测的标签作为输入,可以更好地捕捉到标签之间的上下文信息。
需要注意的是,这些问题转换方法并不是互斥的,可以根据具体的问题和数据集选择合适的方法或者结合不同的方法来解决多标签分类任务。此外,还有其他问题转换方法,如随机子空间法、标签关联规则等,也可以根据具体需求进行尝试。
4.1.3. 标签幂集法(Label Powerset,LP)
标签幂集法将多标签分类问题转化为一个多类分类问题。它将每个可能的标签组合视为一个类别,因此类别的数量等于标签的总数。LP方法的主要挑战是类别的数量通常非常大,因此对于大规模标签空间,LP方法可能变得不可行。然而,在标签空间较小且标签之间没有明显相关性的情况下,LP方法可以提供较好的性能。
4.2. 算法适应方法
算法适应方法是一种直接针对多标签分类任务进行建模的方法,它不需要将问题转化为单标签分类问题。这些方法能够直接处理多个标签的预测,并考虑标签之间的相关性。以下是几种常见的算法适应方法:
4.2.1. 多标签决策树(Multi-Label Decision Trees)
多标签决策树方法通过修改传统的决策树算法,使其适应多标签分类问题。在每个节点上,该方法选择最佳的标签划分方式,并递归地构建一个标签树。相比于传统的单标签决策树,多标签决策树方法能够考虑标签之间的相关性,并直接输出多个标签,从而更好地适应多标签分类任务。
4.2.2. MLKNN(Multi-Label k-Nearest Neighbors):
MLKNN是一种基于k最近邻算法的多标签学习方法。它通过对每个样本的k个最近邻样本进行分析,计算每个标签在这k个最近邻样本中的条件概率。然后,根据条件概率对测试样本进行标签预测。MLKNN考虑了样本之间的标签相关性,能够有效地处理多标签学习任务。
4.2.3. 多标签支持向量机(Multi-Label Support Vector Machines,ML-SVM)
多标签支持向量机方法通过对传统的支持向量机算法进行扩展,以处理多标签分类问题。它引入了额外的阈值技术来处理多个标签的预测。多标签SVM方法在训练阶段可以利用标签之间的相关性来改进分类器性能。通过在高维特征空间中进行优化,多标签支持向量机能够有效地处理多标签分类任务。
需要注意的是,上述方法只是多标签分类领域中的一部分方法,还有其他许多方法在不同的情况下可能更有效。选择适当的方法取决于具体的问题和数据集特征。研究人员在不断提出新的多标签分类方法,并探索不同方法的组合和改进,以提高多标签分类任务的性能和效果。
4.3 基于特征选择的方法:
基于特征选择的方法旨在选择对于多标签预测最具有判别能力的特征子集,以提高多标签学习的效果和效率。其中一种常见的特征选择方法是LIFT(Label Information-based Feature Transformation)。
LIFT是一种基于标签信息的特征选择方法,它利用标签之间的相关性来评估特征的重要性。具体而言,LIFT计算每个特征与每个标签之间的相关性,然后根据相关性评分选择最相关的特征。LIFT方法可以分为两个步骤:特征评估和特征选择。
在特征评估步骤中,LIFT计算每个特征与每个标签之间的相关性得分。常用的相关性度量指标包括互信息、信息增益和相关系数等。这些度量方法能够量化特征和标签之间的相关性程度,从而确定特征的重要性。
在特征选择步骤中,LIFT根据特征与标签之间的相关性得分,选择一部分具有高相关性的特征作为最终的特征子集。可以使用不同的策略来确定选择的特征数量,如设定一个固定的阈值或选择Top-K个特征。
除了LIFT,还有其他一些基于特征选择的方法用于多标签学习。例如,基于信息熵的方法、基于度量学习的方法和基于正则化的方法等。这些方法在评估特征与标签之间的相关性和选择重要特征方面采用不同的策略和技巧。
基于特征选择的方法在多标签学习中起着重要的作用。通过选择最相关的特征子集,可以降低特征维度,提高模型的效率和泛化能力。研究者可以根据具体的数据集和任务需求选择适合的特征选择方法,并结合其他多标签学习方法进行综合应用。
4.4 基于集成学习的方法
基于集成学习的方法将多个单标签分类器集成起来,通过结合它们的预测结果来进行多标签预测。以下是几种常见的基于集成学习的方法:
4.4.1 ECC(Ensemble of Classifier Chains)
ECC是一种基于分类器链的集成学习方法,用于多标签学习。它通过构建多个分类器链来处理多标签问题。每个分类器链都是一个序列,其中每个分类器都根据前面的分类器的预测结果来进行训练和预测。最终的预测结果通过组合所有分类器链的预测结果得到。
4.4.2 D3C(Dynamic Selection of Classifiers)
D3C是一种动态选择分类器的集成学习方法,用于多标签学习。它根据输入样本的特征和标签分布情况,动态地选择最适合的分类器来进行预测。D3C方法根据每个分类器的性能和置信度来选择合适的分类器,并将其预测结果作为最终的多标签预测结果。
4.4.3 Adaboost(Adaptive Boosting)
Adaboost是一种经典的集成学习方法,可以用于多标签学习。它通过迭代训练一系列弱分类器,每个弱分类器都根据前一个分类器的预测错误进行调整。Adaboost会给预测错误的样本更高的权重,以便下一个分类器更关注这些错误的样本。最终的多标签预测结果是基于所有弱分类器的加权投票或加权平均。
这些基于集成学习的方法通过结合多个分类器的预测结果,能够提高多标签学习的性能和鲁棒性。它们可以应对标签之间的相关性和样本不平衡等多标签学习中的挑战。研究者可以根据任务的需求和数据的特点选择适合的集成学习方法,并根据需要进行调优和改进。此外,还可以探索其他集成学习方法来应对多标签学习中的问题。
5. 实验设计
在本节中,我们将讨论实验设计。首先,我们介绍了进行综合研究所采用的实验方法。其次,我们详细介绍了整个实验中使用的特定实验设置。第三,我们给出用于执行实验的特定参数实例化。接下来,我们介绍用于访问方法性能的评估措施。最后,我们讨论了用于分析研究结果的统计评估。
5.1 基准数据集
我们使用了11种不同的多标签分类基准问题,这些问题被广泛用于多标签学习方法的研究和评估。在选择这些问题时,我们考虑了来自不同规模和不同应用领域的基准数据集。下面是数据集的基本统计数据,如表1所示:
Dataset | Domain | #tr.e. | #t.e. | D | Q | lc | |
emotions | Multimedia | 391 | 202 | 72 | 6 | 1.87 | |
scene | Multimedia | 1211 | 1159 | 294 | 6 | 1.07 | |
yeast | Biology | 1500 | 917 | 103 | 14 | 4.24 | |
medical | Text | 645 | 333 | 1449 | 45 | 1.25 | |
enron | Text | 1123 | 579 | 1001 | 53 | 3.38 | |
corel5k | Multimedia | 4500 | 500 | 499 | 374 | 3.52 | |
tmc2007 | Text | 21 519 | 7077 | 500 | 22 | 2.16 | |
mediamill | Multimedia | 30 993 | 12 914 | 120 | 101 | 4.38 | |
bibtex | Text | 4880 | 2515 | 1836 | 159 | 2.40 | |
delicious | Text | 12 920 | 3185 | 500 | 983 | 19.02 | |
bookmarks | Text | 60 000 | 27 856 | 2150 | 208 | 2.03 | |
表1:多标签分类基准数据集的基本统计数据
这些数据集的大小各不相同,训练示例数从391到60,000个不等,测试示例数从202到27,856个不等,特征数从72到2,150个不等,标签数从6到983个不等。每个示例的平均标签数(标签基数)从1.07到19.02不等。这些数据集来自生物学、多媒体和文本分类领域。
在生物学领域,我们使用了酵母数据集,其中基因是数据集中的实例,每个基因可以与14个生物学功能(标签)相关联。
在多媒体领域,我们使用了情感、场景、Corel5k和Mediamill数据集。情感数据集包含音乐示例,每个示例可以贴上六种情绪的标签。场景数据集是一个广泛使用的场景分类数据集,每个场景可以在六个上下文中进行标注。Corel5k数据集包含经过分割和描述的Corel图像,每个图像可以分配几个标签中的一些。Mediamill数据集源自2005年的NIST TRECVID挑战数据集,其中包含有关带注释视频的数据,标签空间由101个"注释概念"表示。
在文本分类领域,我们使用了医学、安然、Tmc2007、美味、Bibtex和书签这六个数据集。医学数据集是在医学自然语言处理挑战赛中使用的数据集,每个实例是一个文档,目标是根据国际疾病分类(ICD-9-CM)为每个文档注释可能的疾病。安然数据集包含来自安然公司高级官员的电子邮件,这些电子邮件被分为几个类别和子类别。Tmc2007数据集包含航空安全报告实例,标签表示报告所描述的问题。美味、Bibtex和书签数据集用于自动标签建议任务,其中美味数据集包含网页及其标签,Bibtex数据集包含论文的元数据,书签数据集包含网页的元数据。
需要注意的是,这些数据集在文献中已经预先分为训练和测试部分,因此在实验中我们使用它们的原始格式。通常情况下,训练部分占完整数据集的约2/3,而测试部分占剩余的1/3。这些多标签分类数据集的选择涵盖了不同领域和不同数据规模,有助于评估多标签学习方法在不同情境下的性能和泛化能力。
5.2 评价指标
在评估多标签算法的性能时,使用了6个成熟的多标签指标,其中包括3个基于分类的指标(准确性、F1测量、汉明损失)和3个基于排名的指标(一个错误、排名损失和平均精度)。
精度(Precision)用于评估真实标签和预测结果之间的Jaccard相似性,其计算公式如下:
精度 = TP / (TP + FP)
其中,TP表示真正例(True Positives),FP表示假正例(False Positives)。精度的取值范围在0到1之间,值越大表示性能越好,完美值为1。
F1测量是精度和召回率的综合度量,用于评估分类器的性能。其计算公式如下:
F1 = 2 (精度 召回率) / (精度 + 召回率)
其中,精度和召回率的计算方式与上述相同。F1的取值范围在0到1之间,值越大表示性能越好,完美值为1。
汉明损失(Hamming Loss)评估错误分类标签的比例,即预测结果与真实标签不一致的比例。其计算公式如下:
汉明损失 = (1 / L) * sum(sum(Y != Y_hat))
其中,L表示标签的总数,Y表示真实标签矩阵,Y_hat表示预测标签矩阵。汉明损失的取值范围在0到1之间,值越小表示性能越好,完美值为0。
一个错误(One-error)评估排名靠前的标签分类不正确的实例的比例。其计算公式如下:
一个错误 = (1 / N) * sum(Y[i, :] != Y_hat[i, :])
其中,N表示实例的数量,Y[i, :]表示第i个实例的真实标签向量,Y_hat[i, :]表示第i个实例的预测标签向量。一个错误的取值范围在0到1之间,值越小表示性能越好,完美值为0。
排名损失(Ranking Loss)评估预测结果中排名靠前的标签分类不正确的实例的比例。其计算公式如下:
排名损失 = (1 / N) sum(rank(Y[i, :]) (Y[i, :] != Y_hat[i, :]))
其中,N表示实例的数量,rank(Y[i, :])表示预测结果向量中第i个实例的标签的秩,Y[i, :]表示第i个实例的真实标签向量,Y_hat[i, :]表示第i个实例的预测标签向量。排名损失的取值范围在0到1之间,值越小表示性能越好,完美值为0。
平均精度(Average Precision)评估预测结果中实际值排名高于特定正标签的正标签的平均比例。其计算公式如下:
平均精度 = (1 / N) * sum(precision_at_k(Y[i, :], Y_hat[i, :]))
其中,N表示实例的数量,precision_at_k(Y[i, :], Y_hat[i, :])表示计算第i个实例的预测结果中与真实标签一致的标签的精度,并取平均值。平均精度的取值范围在0到1之间,值越大表示性能越好,完美值为1。
在进行评估时,以上指标将用于衡量多标签的性能,通过计算预测结果与真实标签之间的差异和相似性,来评估算法的准确性、完整性和排序性能。
5.3实验结果
在本节中,我们将介绍实验评估的完整结果。我们根据评估措施呈现结果。我们首先介绍基于示例的评估措施的结果。然后,我们显示基于标签的评估措施的结果。接下来,我们给出基于排名的评估措施的结果。
Hamming loss
Dataset | BR | CC | CLR |
| HOMER | PCT | ML-kNN | RAkEL | ECC |
emotions | 0.257 | 0.256 | 0.257 |
| 0.361 | 0.267 | 0.294 | 0.282 | 0.281 |
scene | 0.079 | 0.082 | 0.080 |
| 0.082 | 0.129 | 0.099 | 0.077 | 0.085 |
yeast | 0.190 | 0.193 | 0.190 |
| 0.207 | 0.219 | 0.198 | 0.192 | 0.207 |
medical | 0.077 | 0.077 | 0.017 |
| 0.012 | 0.023 | 0.017 | 0.012 | 0.014 |
enron | 0.045 | 0.064 | 0.048 |
| 0.051 | 0.058 | 0.051 | 0.045 | 0.049 |
corel5k | 0.017 | 0.017 | 0.012 |
| 0.012 | 0.009 | 0.009 | 0.009 | 0.009 |
tmc2007 | 0.013 | 0.013 | 0.014 |
| 0.015 | 0.075 | 0.058 | 0.021 | 0.026 |
mediamill | 0.032 | 0.032 | 0.043 |
| 0.038 | 0.034 | 0.031 | 0.035 | 0.035 |
bibtex | 0.012 | 0.012 | 0.012 |
| 0.014 | 0.014 | 0.014 | DNF | 0.013 |
delicious | 0.018 | 0.018 | DNF |
| 0.022 | 0.019 | 0.018 | DNF | DNF |
bookmarks | DNF | DNF | DNF |
| DNF | 0.009 | 0.009 | DNF | DNF |
ranking loss
Dataset | BR | CC | CLR | HOMER | PCT | ML-kNN | RAkEL | ECC |
emotions | 0.246 | 0.245 | 0.264 | 0.297 | 0.270 | 0.283 | 0.281 | 0.310 |
scene | 0.060 | 0.064 | 0.065 | 0.119 | 0.174 | 0.093 | 0.104 | 0.103 |
yeast | 0.164 | 0.170 | 0.163 | 0.205 | 0.199 | 0.172 | 0.259 | 0.224 |
medical | 0.021 | 0.019 | 0.028 | 0.090 | 0.104 | 0.045 | 0.159 | 0.152 |
enron | 0.084 | 0.083 | 0.078 | 0.183 | 0.114 | 0.093 | 0.283 | 0.238 |
corel5k | 0.117 | 0.118 | 0.100 | 0.352 | 0.140 | 0.130 | 0.673 | 0.749 |
tmc2007 | 0.003 | 0.003 | 0.005 | 0.028 | 0.100 | 0.031 | 0.031 | 0.032 |
mediamill | 0.061 | 0.062 | 0.092 | 0.177 | 0.063 | 0.055 | 0.236 | 0.258 |
bibtex | 0.068 | 0.067 | 0.065 | 0.255 | 0.255 | 0.217 | DNF | 0.394 |
delicious | 0.114 | 0.117 | DNF | 0.379 | 0.172 | 0.129 | DNF | DNF |
bookmarks | DNF | DNF | DNF | DNF | 0.258 | 0.181 | DNF | DNF |
one-error
Dataset | BR | CC | CLR | HOMER | PCT | ML-kNN | RAkEL | ECC |
emotions | 0.386 | 0.376 | 0.391 | 0.411 | 0.386 | 0.406 | 0.396 | 0.426 |
scene | 0.180 | 0.204 | 0.190 | 0.216 | 0.389 | 0.242 | 0.197 | 0.213 |
yeast | 0.236 | 0.268 | 0.229 | 0.248 | 0.264 | 0.234 | 0.254 | 0.249 |
medical | 0.135 | 0.123 | 0.168 | 0.216 | 0.612 | 0.279 | 0.312 | 0.315 |
enron | 0.237 | 0.238 | 0.231 | 0.314 | 0.392 | 0.280 | 0.290 | 0.247 |
corel5k | 0.660 | 0.674 | 0.588 | 0.652 | 0.776 | 0.706 | 0.758 | 0.992 |
tmc2007 | 0.029 | 0.026 | 0.033 | 0.050 | 0.306 | 0.190 | 0.047 | 0.052 |
mediamill | 0.188 | 0.193 | 0.586 | 0.219 | 0.220 | 0.182 | 0.234 | 0.242 |
bibtex | 0.346 | 0.342 | 0.388 | 0.466 | 0.783 | 0.576 | DNF | 0.666 |
delicious | 0.354 | 0.367 | DNF | 0.509 | 0.592 | 0.416 | DNF | DNF |
bookmarks | DNF | DNF | DNF | DNF | 0.817 | 0.639 | DNF | DNF |
coverage
Dataset | BR | CC | CLR | HOMER | PCT | ML-kNN | RAkEL | ECC |
emotions | 2.307 | 2.317 | 2.386 | 2.634 | 2.356 | 2.490 | 2.465 | 2.619 |
scene | 0.399 | 0.417 | 0.423 | 0.739 | 0.964 | 0.569 | 0.635 | 0.625 |
yeast | 6.330 | 6.439 | 6.286 | 7.285 | 6.705 | 6.414 | 7.983 | 7.153 |
medical | 1.610 | 1.471 | 2.036 | 5.324 | 5.813 | 2.844 | 8.520 | 7.994 |
enron | 12.530 | 12.437 | 11.763 | 24.190 | 14.920 | 13.181 | 30.509 | 27.760 |
corel5k | 104.800 | 105.428 | 91.506 | 250.800 | 115.676 | 113.046 | 340.398 | 348.160 |
tmc2007 | 1.311 | 1.302 | 1.363 | 2.369 | 4.572 | 2.155 | 2.498 | 2.494 |
mediamill | 20.481 | 20.333 | 24.247 | 47.046 | 20.456 | 18.719 | 56.617 | 58.865 |
bibtex | 20.926 | 21.078 | 18.540 | 65.626 | 58.599 | 56.266 | DNF | 87.841 |
delicious | 530.126 | 537.388 | DNF | 933.956 | 691.622 | 589.898 | DNF | DNF |
bookmarks | DNF | DNF | DNF | DNF | 73.780 | 54.528 | DNF | DNF |
average precision
Dataset | BR | CC | CLR | HOMER | PCT | ML-KNN | RAkEL | ECC |
emotions | 0.721 | 0.724 | 0.718 | 0.698 | 0.713 | 0.694 | 0.713 | 0.687 |
scene | 0.893 | 0.881 | 0.886 | 0.848 | 0.745 | 0.851 | 0.862 | 0.856 |
yeast | 0.768 | 0.755 | 0.768 | 0.740 | 0.724 | 0.758 | 0.715 | 0.734 |
medical | 0.896 | 0.901 | 0.864 | 0.786 | 0.522 | 0.784 | 0.676 | 0.684 |
enron | 0.693 | 0.695 | 0.699 | 0.604 | 0.546 | 0.635 | 0.522 | 0.576 |
corel5k | 0.303 | 0.293 | 0.352 | 0.222 | 0.208 | 0.266 | 0.088 | 0.014 |
tmc2007 | 0.978 | 0.981 | 0.972 | 0.945 | 0.700 | 0.844 | 0.939 | 0.935 |
mediamill | 0.686 | 0.672 | 0.450 | 0.583 | 0.654 | 0.703 | 0.492 | 0.453 |
bibtex | 0.597 | 0.599 | 0.579 | 0.407 | 0.212 | 0.349 | DNF | 0.228 |
delicious | 0.351 | 0.343 | DNF | 0.231 | 0.206 | 0.326 | DNF | DNF |
bookmarks | DNF | DNF | DNF | DNF | 0.213 | 0.381 | DNF | DNF |
F1 score
Dataset | BR | CC | CLR | HOMER | PCT | ML-KNN | RAkEL | ECC |
emotions | 0.469 | 0.461 | 0.465 | 0.614 | 0.554 | 0.431 | 0.525 | 0.556 |
scene | 0.714 | 0.742 | 0.713 | 0.745 | 0.551 | 0.658 | 0.754 | 0.771 |
yeast | 0.650 | 0.657 | 0.655 | 0.687 | 0.578 | 0.628 | 0.661 | 0.670 |
medical | 0.328 | 0.337 | 0.742 | 0.761 | 0.253 | 0.560 | 0.704 | 0.652 |
enron | 0.582 | 0.484 | 0.600 | 0.613 | 0.295 | 0.445 | 0.564 | 0.602 |
corel5k | 0.047 | 0.048 | 0.293 | 0.280 | 0.000 | 0.021 | 0.000 | 0.001 |
tmc2007 | 0.934 | 0.939 | 0.933 | 0.934 | 0.554 | 0.699 | 0.904 | 0.887 |
mediamill | 0.557 | 0.539 | 0.134 | 0.579 | 0.490 | 0.570 | 0.471 | 0.483 |
bibtex | 0.433 | 0.434 | 0.417 | 0.426 | 0.069 | 0.174 | DNF | 0.237 |
delicious | 0.230 | 0.225 | DNF | 0.343 | 0.001 | 0.017 | DNF | DNF |
bookmarks | DNF | DNF | DNF | DNF | 0.135 | 0.213 | DNF | DNF |
5.4 实验结果讨论
根据以上信息提供的信息,我们可以得出以下结论:
在基于示例的评估措施中,HOMER在召回率方面表现最佳,而CLR在精确度方面表现最佳。HOMER的预测更加完整,但会有较多的误报,而CLR的预测更加精确,但可能会错过一些相关标签。
在基于示例的测量中,CLR、HOMER、BR和CC在多个评估措施中表现最佳。CLR在汉明损失和精确度方面表现最佳,HOMER在子集准确性、准确性、召回率和F1得分方面表现最佳。
在基于标签的评估措施中,CLR、HOMER、BR和CC在多个评估措施中表现最佳。HOMER在微精度、微召回、宏观精度和宏观召回方面表现最佳,CLR在宏观精度方面表现最佳。
在基于标签的度量中,集成模型CLR优于单个CLR模型,但集成模型CLR和ECC的性能并不总是优于单个模型。CC是一个稳定的分类器,而CLR选择的特征子集对特征空间进行了欠采样,可能导致性能下降。
基于示例和排名的度量都显示了CLR的优越性,尤其在覆盖率和排名损失方面。基于SVM的方法在较小的数据集上表现较好,而基于树的方法在较大的数据集上表现较好。
需要注意的是,这些结论是根据给定的数据集和评估措施得出的,并且可能因不同的数据集和评估指标而有所不同
6.结论
在这项研究中,我们对多标签学习的方法进行了广泛的实验评估。多标签学习的主题最近得到了大量的研究工作,并引起了研究界的广泛关注。然而,文献中仍然缺乏对这些方法进行更广泛的实验比较。
我们选择了最近在文献中提出的多标签方法,并使用各种数据集和评估措施对它们进行了评估。这些方法分为:算法适配、问题转换。基本机器学习算法的选择包括SVM、决策树和k最近邻等。我们使用了不同的评估措施,以提供多个角度对算法性能进行评估。
需要注意的是,实验比较可以通过包括更多的多标签学习方法来扩展。此外,可以通过纳入其他评估措施来提供更全面的比较。最终的建议是在多标签学习中使用CLR、HOMER、BR和CC这些基准方法,以获得最佳的性能和效率。
参考文献
[1]. Zhang, M., & Zhou, Z. H. (2014). A review on multi-label learning algorithms. IEEE Transactions on Knowledge and Data Engineering, 26(8), 1819-1837.
[2]. Tsoumakas, G., & Katakis, I. (2007). Multi-label classification: An overview. International Journal of Data Warehousing and Mining, 3(3), 1-13.
[3]. Read, J., Pfahringer, B., Holmes, G., & Frank, E. (2011). Classifier chains for multi-label classification. Machine Learning, 85(3), 333-359.
[4]. Zhang, M. L., & Zhou, Z. H. (2007). ML-KNN: A lazy learning approach to multi-label learning. Pattern Recognition, 40(7), 2038-2048.
[5]. Chen, W., Zhang, Y., Zhang, L., & Li, X. (2018). Multi-label classification via feature-aware implicit label space encoding. Neurocomputing, 275, 2627-2636.
[6]. Tsoumakas, G., & Vlahavas, I. (2007). Random k-labelsets: An ensemble method for multilabel classification. International Conference on Machine Learning, 919-926.
[7]. Bi, Y., Kwok, J. T., & Tsang, I. W. (2013). Multi-label learning with label-specific features via sparse and collaborative representation. International Conference on Machine Learning, 315-323.
[8]. Zhang, M., & Zhou, Z. H. (2018). MLC-SVM: A unified multi-label classification method. IEEE Transactions on Neural Networks and Learning Systems, 29(8), 3584-3596.
[9]. Fernández-Delgado, M., Cernadas, E., Barro, S., & Amorim, D. (2014). Do we need hundreds of classifiers to solve real world classification problems? Journal of Machine Learning Research, 15(1), 3133-3181.
[10]. Gibaja, E., Ventura, S., & Herrera, F. (2015). Genetic fuzzy rule-based classification systems for multi-label problems: Two alternatives using linguistic hedges and fuzzy entropy. Fuzzy Sets and Systems, 274, 78-102.
[11]. Dembczyński, K., Waegeman, W., Cheng, W., & Hüllermeier, E. (2010). An analysis of chaining in multi-label classification. Journal of Machine Learning Research, 11, 281-304.
[12]. Boutell, M. R., Luo, J., Shen, X., & Brown, C. M. (2004). Learning multi-label scene classification. Pattern Recognition, 37(9), 1757-1771.
[13]. Zhang, M., & Zhou, Z. H. (2012). A review on multi-label learning algorithms. Big Data Analytics, 1(1), 7.
[14]. Zhang, M. L., & Zhou, Z. H. (2006). Ml-knn: A lazy learning approach to multi-label learning. Machine Learning, 34(1-3), 189-198.
[15]. Zhou, Z. H., Zhang, M. L., & Huang, S. J. (2012). Multi-label learning by exploiting label dependency. Knowledge and Information Systems, 32(3), 491-519.
[16]. Tsoumakas, G., & Katakis, I. (2010). Mining multi-label data. Data Mining and Knowledge Discovery Handbook, 2nd Edition, 667-685.
[17]. Hüllermeier, E., & Chen, W. (2013). A label ranking approach to multi-label classification. In Proceedings of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, 784-799.
[18]. Read, J., & Reutemann, P. (2008). Ml-knn: Instance-based multi-label classification. Multiple Classifier Systems, 39-50.
[19]. Read, J., & Reutemann, P. (2011). Scalable multi-label classification: A case study in online news. Journal of Machine Learning Research, 12, 1725-1751.
[20]. Boutell, M. R., Luo, J., Shen, X., & Brown, C. M. (2004). Learning multi-label scene classification. Pattern Recognition, 37(9), 1757-1771.