
MaXiaoTiao
Encoder
Encoder
Encoder
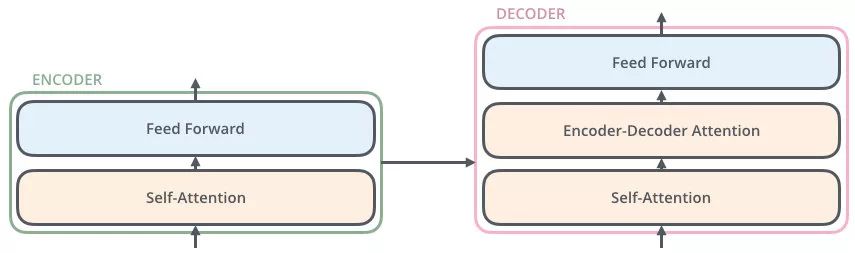
有了上述那么多知识的铺垫,我们知道 Eecoders 是 N=6 层,通过上图我们可以看到每层 Encoder 包括两个 sub-layers:
第一个 sub-layer 是 multi-head self-attention,用来计算输入的 self-attention;
第二个 sub-layer 是简单的前馈神经网络层 Feed Forward;
注意:在每个 sub-layer 我们都模拟了残差网络(在下面的数据流示意图中会细讲),每个sub-layer的输出都是 LayerNorm(x+Sub_layer(x))LayerNorm(x+Sub_layer(x)),其中 sub_layersub_layer 表示的是该层的上一层的输出
现在我们给出 Encoder 的数据流示意图,一步一步去剖析

深绿色的 x1x1 表示 Embedding 层的输出,加上代表 Positional Embedding 的向量之后,得到最后输入 Encoder 中的特征向量,也就是浅绿色向量 x1x1;
浅绿色向量 x1x1 表示单词 “Thinking” 的特征向量,其中 x1x1 经过 Self-Attention 层,变成浅粉色向量 z1z1;
x1x1 作为残差结构的直连向量,直接和 z1z1 相加,之后进行 Layer Norm 操作,得到粉色向量 z1z1;
残差结构的作用:避免出现梯度消失的情况
Layer Norm 的作用:为了保证数据特征分布的稳定性,并且可以加速模型的收敛
z1z1 经过前馈神经网络(Feed Forward)层,经过残差结构与自身相加,之后经过 LN 层,得到一个输出向量 r1r1;
该前馈神经网络包括两个线性变换和一个ReLU激活函数:FFN(x)=max(0,xW1+b1)W2+b2FFN(x)=max(0,xW1+b1)W2+b2
由于 Transformer 的 Encoders 具有 6 个 Encoder,r1r1 也将会作为下一层 Encoder 的输入,代替 x1x1 的角色,如此循环,直至最后一层 Encoder。
需要注意的是,上述的 x、z、rx、z、r 都具有相同的维数,论文中为 512 维。