
MaXiaoTiao
How to Fine-Tune BERT for Text Classification?

How to Fine-Tune BERT for Text Classification?
复旦大学邱锡鹏老师课题组的研究论文《How to Fine-Tune BERT for Text Classification?》。
论文: https://arxiv.org/pdf/1905.05583.pdf
作者的实现代码: https://github.com/xuyige/BERT4doc-Classification
数据集来源:https://www.kaggle.com/shivanandmn/multilabel-classification-dataset?select=train.csv(该数据集包含 6 个不同的标签(计算机科学、物理、数学、统计学、生物学、金融),以根据摘要和标题对研究论文进行分类。标签列中的值 1 表示标签属于该标签。每个论文有多个标签为 1)
这篇论文的主要目的在于在文本分类任务上探索不同的BERT微调方法并提供一种通用的BERT微调解决方法。这篇论文从三种路线进行了探索:
(1) BERT自身的微调策略,包括长文本处理、学习率、不同层的选择等方法;
(2) 目标任务内、领域内及跨领域的进一步预训练BERT;
(3) 多任务学习。微调后的BERT在七个英文数据集及搜狗中文数据集上取得了当前最优的结果。
本论文的主要贡献如下:
我们提出了一种微调预训练BERT模型的通用解决方案,它包括三个步骤:
(1)进一步对任务内训练数据或域内数据进行BERT预训练;
(2)如果有多个相关任务可用,则可选择使用多任务学习来微调BERT;
(3)针对目标任务微调BERT。
我们还研究了目标任务中ERT的微调方法,包括长文本的预处理、层选择、层级学习率、灾难性遗忘、和小样本的学习问题。我们在七个广泛研究的英文文本分类数据集和一个中文新闻分类数据集上实现了新的最先进的结果。
BERT for Text Classification
BERT-base 模型包含一个编码器,其中包含 12 个 Transformer 块、12 个自注意力头和 768 的隐藏大小。 BERT 接受不超过 512 个标记的序列的输入并输出序列的表示。该序列有一个或两个段,序列的第一个标记总是 [CLS],其中包含特殊的分类嵌入,另一个特殊标记 [SEP] 用于分离段。
对于文本分类任务,BERT 将第一个标记 [CLS] 的最终隐藏状态 h 作为整个序列的表示。在 BERT 的顶部添加了一个简单的 softmax 分类器来预测标签 c 的概率。
其中 W 是特定于任务的参数矩阵。我们通过最大化正确标签的对数概率来联合微调 BERT 和 W 中的所有参数。
Methodology
当我们将 BERT 适应目标域中的 NLP 任务时,需要适当的微调策略。在本文中,我们以以下三种方式查看适当的微调方法。
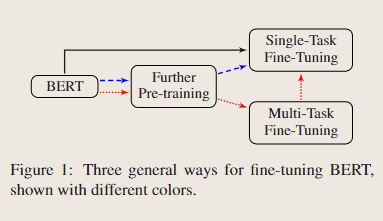
1) 微调策略:当我们为目标任务微调BERT时,有很多方法可以利用BERT。例如,BERT的不同层捕获不同层次的语义和句法信息,哪个层更适合目标任务?我们如何选择更好的优化算法和学习率?
2)进一步的预训练:BERT 在一般领域进行训练,其数据分布与目标域不同。一个自然的想法是进一步使用目标域数据预训练 BERT。
3) 多任务微调:在没有预训练的LM模型的情况下,多任务学习显示了其利用多个任务之间共享知识的有效性。当目标域中有多个可用任务时,一个有趣的问题是,在所有任务上同时微调BERT是否仍能带来好处?
Fine-Tuning Strategies
神经网络的不同层可以捕获不同层次的句法和语义信息
为了使 BERT 适应目标任务,我们需要考虑几个因素:1)第一个因素是长文本的预处理,因为 BERT 的最大序列长度为 512。 2)第二个因素是层选择。官方的基于 BERT 的模型由一个嵌入层、一个 12 层编码器和一个池化层组成。我们需要为文本分类任务选择最有效的层。3) 第三个因素是过拟合问题。需要具有适当学习率的更好的优化器。
我们将参数 θ 拆分为 {θ1, · · · , θL},其中 θl 包含 BERT 的第 l 层的参数。
将基础学习率设置为 ηL 并使用 ηk−1 = ξ · ηk,其中 ξ 是一个衰减因子,小于或等于 1。当 ξ < 1 时,下层的学习率低于较高层。当 ξ = 1 时,所有层都有相同的学习率,相当于常规随机梯度下降 (SGD)。
4.2 Further Pre-training
BERT模型在通用领域语料库中进行了预训练。对于特定领域的文本分类任务,例如电影评论,其数据分布可能与BERT不同。因此,我们可以在特定领域的数据上进一步用掩蔽语言模型和下一句预测任务来预训练Bert。进一步进行三种预训练方法:
1) 任务内预训练,其中 BERT 在目标任务的训练数据上进一步预训练。
2) 域内预训练,其中预训练数据是从目标任务的相同域中获得的。例如,有几个不同的情感分类任务,具有相似的数据分布。我们可以在这些任务的组合训练数据上进一步预训练 BERT。3) 跨域预训练,其中预训练数据是从相同域和其他不同域到目标任务获得的。
4.3 Multi-Task Fine-Tuning
多任务学习也是共享多个相关监督任务中获得的知识的有效方法。与Liu等人(2019)类似,我们也在多任务学习框架中使用微调BERT进行文本分类。所有任务共享BERT层和嵌入层。唯一不共享的层是最终的分类层,这意味着每个任务都有一个私有的分类器层。
5 Experiments
我们研究了7个英文和1个中文文本分类任务的不同微调方法。我们使用基本BERT模型BERT-base模型和对中文处理的的BERT-base模型。
5.1 Datasets
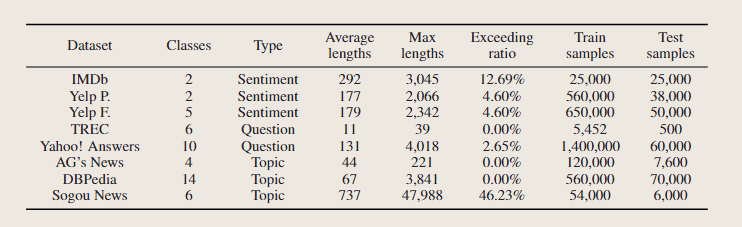
我们在八个数据集上对我们的方法进行了评估。这些数据集具有不同数量的文本和不同的文本长度,涵盖三个常见的文本分类任务:情感分析、问题分类和主题分类。对于情感分析,我们使用电影评论IMDb数据集和Yelp评论数据集。问题分类我们用TREC数据集和Yahoo!与其他文档级数据集相比,TREC数据集是语句级的,其训练实例较少。雅虎!Answers数据集是一个拥有1400k个训练样本的大数据集。为了测试BERT 对中文文本的有效性,我们为搜狗新闻语料库创建了中文训练和测试数据集。我们选择 6 个类别——“体育”、“房子”、“商业”、“娱乐”、“女性”和“技术”。为每个类选择的训练样本数量为9000个,测试1000个。
5.2 Hyperparameters
主要讲了对bert的进一步预训练和微调来进行文本分类的内容,分别讨论微调BERT的方法流程。
我们使用基于Bert的模型(Devlin等人,2018),隐藏大小为768,12个Transformer块和12个self-attention头。
批次大小为32,最大序列长度为128,学习率为5E-5,训练步数为10万步,预热步数为1万步。
基础学习率为 2e-5,热身比例为 0.1。我们根据经验将 epoch 的最大数量设置为 4,并在验证集上保存最佳模型进行测试。
5.3 Exp-I: Investigating Different Fine-Tuning Strategies
在本小节中,我们使用 IMDb 数据集来研究不同的微调策略。官方预训练模型设置为初始编码器5
5.3.1 Dealing with long texts
BERT的最大序列长度为512。将BERT应用于文本分类的第一个问题是如何处理长度大于512的文本。我们尝试了以下方法来处理长文章。截断方法,通常文章关键信息在开始和结束。我们使用三种不同的截断文本方法来执行 BERT 微调。
仅头:保留前 510 个标记6;
仅尾:保留最后 510 个标记;
head+tail:根据经验选择前 128 个标记和最后 382 个标记。
分层方法首先将输入文本分成k=L/510个分数,然后将其输入BERT以获得k个文本分数的表示。每个分数的表示是最后一层的[CLS]标记的隐藏状态。然后我们使用平均池、最大池和自我关注来组合所有分数的表示。表2显示了上述方法的有效性。头部+尾部的截断方法在IMDb和搜狗数据集上实现了最佳性能。因此,我们在以下实验中使用此方法处理长文本
5.3.2 Features from Different layers
BERT的每一层都捕捉到了输入文本的不同特征。我们研究了来自不同层的特征的有效性。然后我们微调模型并记录测试错误率的性能。表 3 显示了使用不同层微调 BERT 的性能。BERT 的最后一层给出了最佳性能。因此,我们将此设置用于以下实验
5.3.3 Catastrophic Forgetting
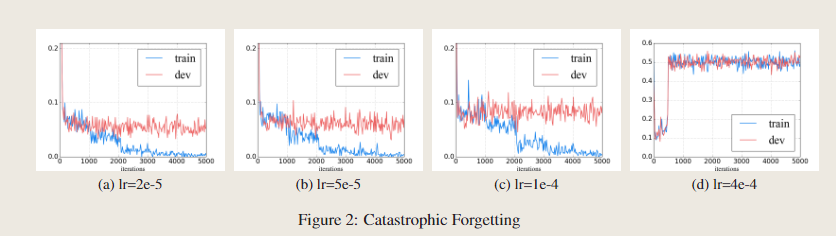
灾难性遗忘(McCloskey 和 Cohen,1989)通常是迁移学习中的一个常见问题,这意味着在学习新知识时会擦除预训练的知识。因此,我们还研究了 BERT 是否存在灾难性遗忘问题。我们用不同的学习率微调 BERT,IMDb 上的错误率学习曲线如图 2 所示。
我们发现较低的学习率,例如 2e-5,对于使 BERT 克服灾难性遗忘问题是必要的。具有 4e-4 的积极学习率,训练集无法收敛。
5.3.4 Layer-wise Decreasing Layer Rate
表4显示了IMDb数据集上不同基础学习率和衰减因子(见等式(2))的性能。我们发现,将较低的学习速率分配给较低的层对于微调BERT是有效的,并且适当的设置为ξ=0.95和lr=2.0e-5。
5.4 Exp-II: Investigating the Further Pretraining
此外,通过监督学习微调BERT,我们可以通过无监督掩蔽语言模型和下一句预测任务在训练数据上进一步预训练BERT。在本节中,我们将调查进一步预培训的有效性。在接下来的实验中,我们在微调阶段使用实验I中的最佳策略。
5.4.1 Within-Task Further Pre-Training
因此,我们首先研究了任务内进一步预训练的有效性。我们采用了进一步具有不同步骤的预训练模型,然后使用文本分类任务对其进行微调。如图 3 所示,进一步的预训练对于提高 BERT 在目标任务上的性能很有用,这在 100K 训练步骤后实现了最佳性能。
5.4.2 In-Domain and Cross-Domain Further Pre-Training
除了目标任务的训练数据外,我们还可以对来自同一域的数据进一步预训练 BERT。在本小节中,我们研究了使用域内和跨域数据进一步预训练 BERT 是否可以继续提高 BERT 的性能。
我们将七个英语数据集分为三个领域:主题、情感和问题。分区方式不是严格正确的。因此,我们还对跨任务预训练进行了广泛的实验,其中每个任务都被视为一个不同的领域。
结果如表5所示。我们发现,几乎所有进一步的预训练模型在所有7个数据集上的表现都优于原始的BERTbase模型(表5中的第“w/o pretrain”)。一般来说,域内预训练可以带来比任务内预训练更好的性能。
在小句子水平的TREC数据集上,任务内预训练对成绩有不利影响,而域内预训练利用Yah。答:语料库在TREC上可以取得更好的结果。通常不会带来明显的好处。这是合理的,因为伯特已经接受了一般领域的培训。我们还发现,IMDb和Yelp在情感领域并不相互帮助。原因可能是IMDb和Yelp是电影和食物的两个情感任务。数据分布有显著差异。
5.4.3 Comparisons to Previous Models
我们将我们的模型与以下各种不同的方法进行了比较:基于CNN的方法VDCNN和DPCNN;基于RNN的方法,如D-LSTM、Skim-LSTM和分层注意网络;基于特征的迁移学习方法,如Rigon Embedding和Cove;以及语言模型微调方法ULMFiT,这是当前文本分类的最新技术。
如表 6 所示,BERT-Feat 的性能优于除 ULMFiT 之外的所有其他基线。除了在 DBpedia 数据集上比 BERTFeat 稍差之外,BERT-FiT 在其他七个数据集上的表现也优于 BERT-Feat。此外,三个进一步的预训练模型都优于 BERT-FiT 模型。使用 BERT-Feat 作为参考,我们计算每个数据集上其他 BERT-FiT 模型的平均百分比增加。BERT-IDPT-FiT 表现最好,平均错误率降低了 18.57%。
5.5 Exp-III: Multi-task Fine-Tuning
当文本分类任务有几个数据集时,为了充分利用这些可用数据,我们进一步考虑了多任务学习的微调步骤。我们使用四个英文文本分类数据集(IMDb、Yelp P.、AG 和 DBP)。数据集 Yelp F。被排除在外,因为 Yelp F 的测试集之间存在重叠。和 Yelp P. 的训练集,也排除了两个问题域数据集。我们分别在所有七个英语分类数据集上进行了实验官方 uncased BERTbase 权重和权重进一步预训练。为了为每个子任务获得更好的分类结果,在一起微调后,我们以较低的学习率微调各自数据集上的额外步骤。
表 7 显示,对于基于 BERT 的多任务微调,效果得到了改善。然而,多任务微调似乎并没有帮助多任务微调和跨域预训练可能是替代方法,因为 BERT-CDPT 模型已经包含丰富的特定领域信息,多任务学习可能不足以提高相关文本分类子任务的泛化。
5.6 Exp-IV: Few-Shot Learning
预训练模型的好处之一是能够在小型训练数据中为下游任务训练模型。我们在不同数量的训练示例上评估 BERT-FiT 和 BERT-ITPT-FiT。我们选择 IMDb 训练数据的一个子集并将它们输入 BERT-FiT 和 BERTITPT-FiT。我们在图 4 中展示了结果。
该实验结果表明,BERT 对小尺寸数据带来了显着的改进。进一步预训练的 BERT 可以进一步提高其性能,仅用 1.26% 提高到 9.23% 的错误率
6 Conclusion
在本文中,我们进行了广泛的实验来研究为文本分类任务微调 BERT 的不同方法。有一些实验结果:
1)BERT 的顶层对文本分类更有用;
2)通过适当的逐层递减学习率,BERT 可以克服灾难性遗忘问题;
3)任务内和域内进一步的预训练可以显着提高其性能;
4)之前的多任务微调也有助于单任务微调,但其好处小于进一步的预训练;
5)BERT 可以用小尺寸数据改进任务。
模型微调的策略从以下几个方法开展:
处理文本的长度。
1)截断:一般来说文本中最重要的信息是开始和结尾,对于长文本做了截断处理。
head-only:保留前510个字符
tail-only:保留后510个字符
head+tail:保留前128个和后382个字符
head+tail方法被证明是有效的,具有最佳的性能;
2)切分:先将长文本切割成 K = L / 510 个片段,之后分别取不同片段的向量表示。不同网络层的特征选择。挑选合适的层用于分类任务,很明显,用最后一层还是比较靠谱的。
灾难性遗忘。使用BERT时尽量使用小的学习率,模型能够有效、快速收敛,2e-5
进一步预训练,训练的步数太少达不到效果,太多会造成灾难性遗忘,选择100K作为一个训练步数是合理的。
5.多任务实验效果,对目标中的多个任务同时微调BERT是否有效果。
BERT-ITPT-FiT = “BERT + withIn-Task Pre-Training + Fine-Tuning”.
BERT-IDPT-FiT = “BERT + In-Domain Pre-Training + Fine-Tuning”.
BERT-CDPT-FiT = “BERT + Cross-Domain Pre-Training+ Fine-Tuning”.
有用的信息:
1.合适的学习率和层宽能够有助于BERT克服灾难性遗忘;
2. 进一步预训练可以显著提高对任务处理的性能
3. 预训练语言模型BERT的最后一层较于其他层来说更加有助于分类