
MaXiaoTiao
Multi-head Self Attention
Multi-head Self Attention
Multi-head Self-Attention 是 Transformer 架构中的一个核心组成部分,它允许模型在不同的表示子空间中并行地学习信息,这有助于捕获输入序列中的复杂关系。以下是 Multi-head Self-Attention 的详细解释:
基本概念
Self-Attention: 自注意力机制是一种注意力机制,其中查询(Query)、键(Key)和值(Value)都来自于同一个输入序列。它允许模型在处理序列时考虑序列中的每个元素如何与其他元素相关。
Multi-head: 多头注意力意味着将输入分割成多个“头”进行处理,每个头都有自己的参数集。这些头并行地执行自注意力机制,并且它们的输出随后被组合起来。
工作原理
线性变换: 输入序列首先通过三个不同的线性变换(权重矩阵)被转换为查询(Q)、键(K)和值(V)。
多头分割: 这些变换后的 Q、K 和 V 被分割成多个头,每个头处理输入序列的一部分。
并行自注意力: 每个头独立地执行自注意力机制,计算每个位置的输出。
输出合并: 所有头的输出被连接起来,并通过另一个线性层进行变换,以生成最终的输出。
计算步骤
以下是 Multi-head Self-Attention 的计算步骤:
线性变换:
Q = WQ * X
K = WK * X
V = WV * X 其中 WQ, WK, WV 是可学习的权重矩阵,X 是输入序列。
多头分割:
将 Q、K 和 V 分割成 h 个头,每个头得到一部分 Q、K 和 V。
自注意力计算: 对于每个头 i:
计算注意力得分:S = Qi * Ki^T / √d
应用 softmax 函数:A = softmax(S)
计算输出:Oi = A * Vi
输出合并:
连接所有头的输出:O = concatenate([O1, O2, …, Oh])
应用最终的线性变换:Z = WO * O 其中 WO 是另一个可学习的权重矩阵。
优点
并行处理: 多头注意力允许模型并行地处理信息,这可以加速训练和推理过程。
不同子空间: 每个头可以学习输入序列的不同表示,这有助于模型捕捉到不同类型的关系。
增加模型容量: 多头注意力增加了模型的表达能力,因为它可以同时关注输入序列的不同部分。
Multi-head Self-Attention 的架构
分割注意力: 首先,我们将输入序列通过自注意力机制得到一个注意力值矩阵 Z。然后,我们将这个矩阵 Z 切分成多个头(例如8个头),每个头得到一个子矩阵 Zi。
并行处理: 每个头 Zi 独立地进行自注意力计算,这相当于在每个子空间中分别学习输入序列的不同表示。
重新组合: 计算完所有头的自注意力后,我们将这些子矩阵 Zi 拼接起来,形成一个大的矩阵。
线性变换: 为了确保输出与输入的结构相同,我们会对拼接后的矩阵进行一次线性变换(乘以一个权重矩阵 W0),得到最终的输出矩阵 Z’。
Multi-head Self-Attention 的优点
捕捉不同子空间的信息: 通过将输入序列分割成多个头,每个头可以在不同的子空间中学习信息。这意味着模型可以同时关注输入序列的不同方面,比如语法结构、语义内容等。
增强模型的表达能力: 多头注意力允许模型在不同的表示空间中捕捉到更丰富的特征信息,这增强了模型的整体表达能力。
并行计算: 由于每个头是独立计算的,因此可以并行处理,这提高了计算效率。
灵活性: 多头注意力机制使得模型更加灵活,能够适应不同的任务需求。
图解
以下是一个简化的图解,展示了 Multi-head Self-Attention 的流程:
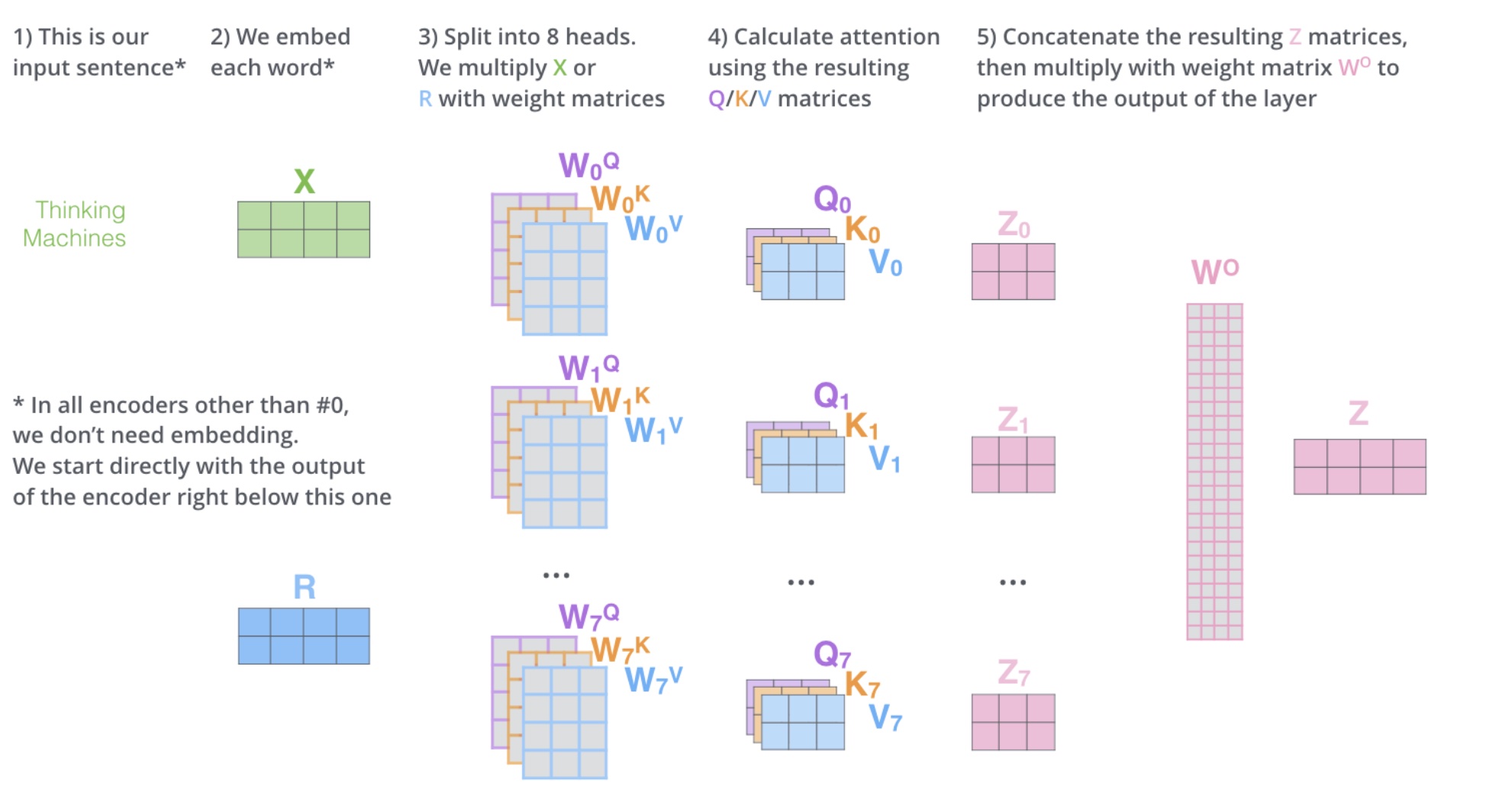
输入序列 -> 自注意力机制 -> 得到 Z
Z -> 切分成多个头 (Z1, Z2, ..., Zn)
每个头独立计算自注意力 -> 得到多个子矩阵 (Z1', Z2', ..., Zn')
拼接 (Z1', Z2', ..., Zn') -> 得到拼接后的矩阵
拼接后的矩阵 -> 线性变换 (乘以 W0) -> 得到最终输出 Z'