
MaXiaoTiao
Multi label

多标签分类方法
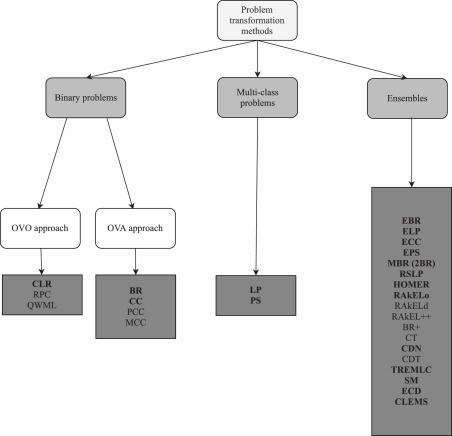
问题转换方法( Problem Transformation)
Classifier chains for multi-label classification
“Read J, Pfahringer B, Holmes G, et al. Classifier chains for multi-label classification[J]. Machine learning, 2011, 85: 333-359.”
Classifier Chains是一种用于多标签分类的问题转换方法。它的基本思想是将多标签学习问题转换为一系列的二分类问题,其中每个二分类器负责预测一个标签的相关性,同时利用前面的二分类器的预测结果作为额外的输入特征,这样一个链式的结构,不断地进行累加,分类器链可以在保持二分类器的计算效率的同时,相比之前的多标签二元分类方法,考虑到了标签之间的相关性。
特点
提出了一种新颖的基于二元相关性方法Binary Relevance的多标签分类方法,克服了二元相关性方法忽略标签相关性的缺点。
优点
它利用了二元相关性方法的可扩展性和灵活性,可以灵活使用其他的单标签分类器作为基础学习器。
通过引入额外的特征来建立标签之间的联系,而不需要复杂地建模标签之间的依赖关系。
缺点
对标签集过大的数据集不太适用。
对链式结构上的沿链标签排序的依赖性,对其标签的排序比较敏感。
Multilabel classification via calibrated label ranking
“Fürnkranz J, Hüllermeier E, Loza Mencía E, et al. Multilabel classification via calibrated label ranking[J]. Machine learning, 2008, 73: 133-153.”
这篇论文的方法是基于校准标签排序(Calibrated Label Ranking,简称CLR)的多标签分类方法。该方法的核心思想是将多标签分类问题转化为标签排序问题,即对每个样本,给出所有可能标签的偏好顺序,并通过引入一个人工的校准标签,将排序分割为相关和不相关的两部分。该方法利用了成对比较的技术,为每一对标签(包括校准标签)训练一个二元分类器,然后通过投票机制得到最终的标签排序。该方法可以看作是结合了成对偏好学习和传统的相关性分类技术,前者用于预测标签之间的相对顺序,后者用于预测标签是否与样本相关。
特点
它可以同时解决多标签分类和排序两个问题,而不仅仅是给出一个最优的标签集合。
它可以处理不完整或嘈杂的训练数据,即不需要每个样本都有完整的标签偏好或分割信息。
优点
它可以有效地利用多种类型的训练信息,包括成对偏好、相关性和不相关性。它可以提供更丰富和灵活的输出形式,既可以给出一个全序排列,也可以给出一个部分排列或一个二分划分。它可以在一些实际应用中表现出较好的效果,例如文本分类、图像分类和基因分析。
缺点
它需要训练大量的二元分类器,这会增加计算复杂度和存储开销,所以探索空间和时间复杂度大,它不太适合具有大量标签的数据集。
Random k-labelsets for multilabel classification
“Tsoumakas G, Katakis I, Vlahavas I. Random k-labelsets for multilabel classification[J]. IEEE transactions on knowledge and data engineering, 2010, 23(7): 1079-1089.”
RAkEL,即随机k标签集,是一种基于集成学习的多标签分类方法。它的主要思想是将原始的多标签问题分解为多个子问题,每个子问题只涉及一小部分随机选择的标签,即在标签空间的随机分区上训练的多个 LP 模型,然后使用单标签分类器来对每个子集进行分类。最后,将所有子问题的预测结果通过投票的方式进行融合,得到最终的多标签分类结果。
特点
它可以有效地利用标签之间的相关性,因为每个子问题都包含了一些标签的组合,而不是像BR方法那样忽略标签之间的关系。
它可以降低计算复杂度,因为每个子问题都只涉及少量的标签和类别,而不是像标签幂集(LP)方法那样面临指数级增长的类别数。
优点
有效地利用标签之间的相关性,和相比LP来说较低的复杂性。
提高预测性能,因为它使用了集成学习的思想,通过多个不同的集来提供多样化的分类器和纠正潜在的错误。
缺点
它需要额外地存储和训练多个子集的模型,可能会占用较多的内存和时间资源。
它需要随机地选择子问题涉及的标签集合,可能会导致一些重要或者稀有的标签被忽略或者过度表示。
它需要确定合适的参数k和m,可能会受到数据集本身特征和单标签分类器性能的影响。
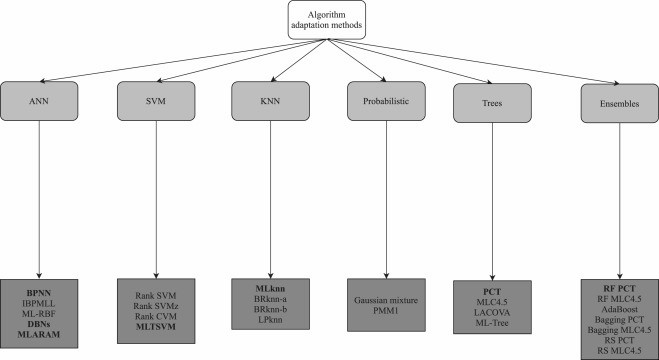
算法自适应(Algorithm Adaptation,AA)
ML-kNN: A lazy learning approach to multi-label learning. Pattern Recognition
“Zhang M-L, Zhou Z-H. ML-kNN: A lazy learning approach to multi-label learning. Pattern Recognition, 2007, 40(7): 2038-2048”
Ml-knn是一种基于k近邻算法的多标签学习方法,它的思想是利用统计信息来确定每个未标注样本的标签集合。具体来说,对于每个未标注样本,Ml-knn首先在训练集中找出其k个最近邻样本,然后根据这些邻居样本的标签集合,计算每个可能标签出现的次数,即成员计数向量。接着,Ml-knn使用最大后验原则,根据先验概率和后验概率,判断每个可能标签是否属于未标注样本的标签集合,先验概率和后验概率都可以从训练集中直接估计。最后的分类结果是通过,计算对比这个标签的支持度和反支持度来进行对比,得出多标签结果。
特点:
它是一种懒惰学习方法,即不需要在训练阶段构建一个显式的分类器,而是在测试阶段根据邻居样本动态地进行分类。
它是一种基于算法适应的方法,即它将单标签分类方法对其使用到多标签方法上,来进行应用,方法相对于其他方法,比较简单,处理速度较快。
优点:
它是一种简单而有效的多标签学习方法,它只需要调整一个参数k,就可以实现较好的分类性能。
它可以利用已有的kNN算法和距离度量来实现,它不需要设计复杂的模型或优化算法。
缺点:
它需要存储整个训练集,这会占用较大的内存空间,并且在测试阶段需要遍历训练集来寻找最近邻样本,这会增加较大的时间开销。
它对噪声数据和异常数据比较敏感,因为它完全依赖于邻居样本的信息来进行分类,如果邻居样本中存在错误或离群点,会影响分类结果。
它没有考虑到不同标签之间可能存在不同程度的相关性,它只是简单地统计了每个标签出现的次数,并没有区分不同标签对应的权重或重要性,并且对k值较为依赖。
A kernel method for multi-labelled classification
“Elisseeff A, Weston J. A kernel method for multi-labelled classification[J]. Advances in neural information processing systems, 2001, 14.”
该方法是基于支持向量机(SVM)的多标签分类方法,称为Rank-SVM。这个方法的基本思想是将多标签问题转化为一个排序问题,即对每个样本,根据其属于不同标签的可能性,对所有标签进行排序。然后,通过定义一个基于间隔的目标函数和一个基于排名损失的惩罚项,来优化一个二次规划问题,得到一个线性或非线性的分类器,进行多标签的分类。
特点
它可以直接处理多标签问题,而不需要将其分解为多个二分类问题或多分类问题,从而避免了忽略标签之间的相关性和结构的问题。
它可以使用核函数来增加模型的表达能力和灵活性,从而适应非线性和复杂的数据分布。
它可以利用间隔最大化和正则化来控制模型的复杂度和泛化能力,从而避免过拟合或欠拟合的问题。
优点
可以直接处理一些具有多标签特征的实际问题,在ranking loss 上表现比其他的方法更好。
缺点
它需要解决一个二次规划问题,这在计算上可能比较复杂和耗时,尤其是当数据集很大或者标签集很多时。
它需要选择合适的参数,并且因为最大间隔对噪声非常敏感。
MLTSVM: A novel twin support vector machine to multi-label learning
“Chen W J, Shao Y H, Li C N, et al. MLTSVM: A novel twin support vector machine to multi-label learning[J]. Pattern Recognition, 2016, 52: 61-74.”
这篇论文的方法是基于孪生支持向量机TWSVM的多标签分类算法,称为多标签孪生支持向量机(MLTSVM)。TWSVM是一种二分类算法,它通过构造两个非平行的超平面来划分两类样本,每个超平面都尽可能地靠近自己的类别,而远离另一个类别。MLTSVM将TWSVM扩展到多标签问题,即每个样本可能属于多个类别(有点类似自己的方法)。MLTSVM的基本思想是为每个类别构造一个超平面,使得该超平面靠近属于该类别的样本,而远离不属于该类别的样本。
特点
它是第一个将TWSVM应用到多标签问题的算法。
它利用了多标签信息,通过求解一系列二次规划问题来构造多个非平行超平面,得出多标签分类结果。
它提出了一个简单而有效的预测策略,根据测试样本到不同超平面的距离来确定其标签集合,能够克服测试过程中的模糊情况,降低误分类概率。
缺点
没有考虑到标签之间可能存在的相关性和依赖性,而只是将每个标签视为独立的二分类问题。这可能导致忽略了一些重要的信息,影响了分类效果。
ML-TREE: A tree-structure-based approach to multilabel learning
“Wu Q, Ye Y, Zhang H, et al. ML-TREE: A tree-structure-based approach to multilabel learning[J]. IEEE transactions on neural networks and learning systems, 2014, 26(3): 430-443.”
这篇论文的方法是ML-Tree,它是一种基于树结构的多标签学习方法。它的主要思想是将每个节点上使用一对多的SVM分类器来递归地划分数据集。为了处理多标签预测,它在每个节点上定义了一个预测标签向量(PLV,如果两个标签作为预测标签在叶节点上频繁出现,则这些标签应该是相关的),用来表示该节点的预测标签和标签之间的关系。预测标签是通过节点的类别纯度(CPV)和一个阈值参数λ来确定的。预测标签会在树结构中自上而下地传递,从而保留了标签之间的相关性。最终,对于一个未知的样本,它会根据其所到达的叶子节点的PLV来给出多标签预测。
特点
它使用了一种分治的策略来构建一个层次化的树模型,可以有效地处理大规模和高维度的多标签数据集。
引入了PLV和CPV两个重要的概念,可以在树模型中传递和利用标签之间的相关信息。自动发现标签之间的关系,不需要事先给定一个标签层次结构或者依赖于其他特征选择或降维技术。
优点
有效地利用标签之间的相关性来提高 多标签预测的准确性。
不同级别的多个一对一 SVM 分类器可以有效地协同工作,以揭示标签之间的相关性,并更精确地预测实例的标签。
缺点
由于学习分类器层次结构的计算成本很高,以及对阈值参数λ进行交叉验证来选择最优值,所以这会增加训练时间和内存消耗。
讨论
问题转化算法是将多标签问题进行降级,转化为其他单分类或者多分类 类型的问题,然后使用单标签算法进行处理。这些算法通过将多标签问题分解为多个单标签子问题来解决。
算法适应算法是在现有的单标签算法基础上进行适应,以处理多标签问题。这些算法试图修改或扩展单标签算法,使其能够适用于多标签情况。
问题转化算法和算法适应算法的主要区别在于处理多标签问题的方法。
问题转化算法尝试将多标签问题转化为其他类型的问题,然后使用单标签算法进行处理。这种方法假设各个标签之间是相互独立的,在处理多标签数据时可能会忽略标签之间的关联性和交互作用,所以在很多关于问题转化算法的论文中都可看到探讨标签相关性的讨论,并且一般在其基础上还分为一阶、二阶、三阶的方法。
而算法适应算法则是在现有的单标签算法基础上进行修改,以考虑标签之间的相关性和复杂性,更直接地处理多标签数据。这种方法致力于将单标签算法扩展为多标签情境,以更好地捕获标签之间的相互影响。
现有的集成方法大多为问题转化算法的集成,一般为多个单标签分类器进行组合,每个标签都被视为一个独立的二分类任务,因此可以为每个标签设置独立的阈值,然后多个分类器对多个单标签得出分类结果,一般使用投票方法,得出多标签分类结果。
而算法适应算法因为从一开始改造就奔着多标签来进行,更直接地处理多标签问题,通常会尝试在单标签算法的基础上考虑标签之间的关联性。这意味着阈值的设置可能更复杂,因为你需要考虑标签之间的交互作用。在最后的阈值选择也都是各种各样的阈值条件来进行选择,基本为标签的相关度和不相关度的比较或者设置其他阈值条件来进行抉择。