
MaXiaoTiao
神经网络语言模型
神经网络语言模型
神经网络语言模型是一种利用神经网络来预测语言序列中下一个词或字符的模型。与传统的统计语言模型相比,神经网络语言模型能够捕捉到更复杂的语言特征和模式,因为它可以通过多层非线性变换来学习数据中的高级抽象。
以下是神经网络语言模型的一些关键点:
模型架构:
循环神经网络(RNN):最早的神经网络语言模型之一,通过循环连接来维持序列信息。
长短期记忆网络(LSTM):一种特殊的RNN,能够更好地处理长序列问题,避免传统RNN的梯度消失问题。
门控循环单元(GRU):LSTM的变体,结构更简单,但同样能够处理长序列。
Transformer:一种基于自注意力机制的模型,能够同时处理序列中的所有位置,极大地提高了语言模型的效果。
训练过程:
神经网络语言模型通常在大规模文本语料库上进行训练,学习预测给定前文的情况下下一个词的概率。
训练时,网络的输入是前文的一个词或一个词序列,输出是对应的词或字符的概率分布。
损失函数:
在训练过程中,通常使用交叉熵损失函数来衡量模型预测的概率分布与真实分布之间的差异。
优点:
能够捕捉到复杂的语言特征,如词义、语法和上下文关系。
通过预训练,可以在多种不同的语言任务上进行微调,实现跨任务的迁移学习。
挑战:
训练大规模神经网络语言模型需要大量的计算资源。
需要处理数据稀疏性和过拟合问题。
应用:
文本生成:生成文章、对话等。
机器翻译:将一种语言的文本翻译成另一种语言。
语音识别:将语音转换为文本。
文本理解:用于问答系统、情感分析等。
神经网络语言模型的发展极大地推动了自然语言处理领域的发展,尤其是在预训练模型方面,如BERT(Bidirectional Encoder Representations from Transformers)、GPT(Generative Pre-trained Transformer)等,它们在多种NLP任务上都取得了显著的性能提升。
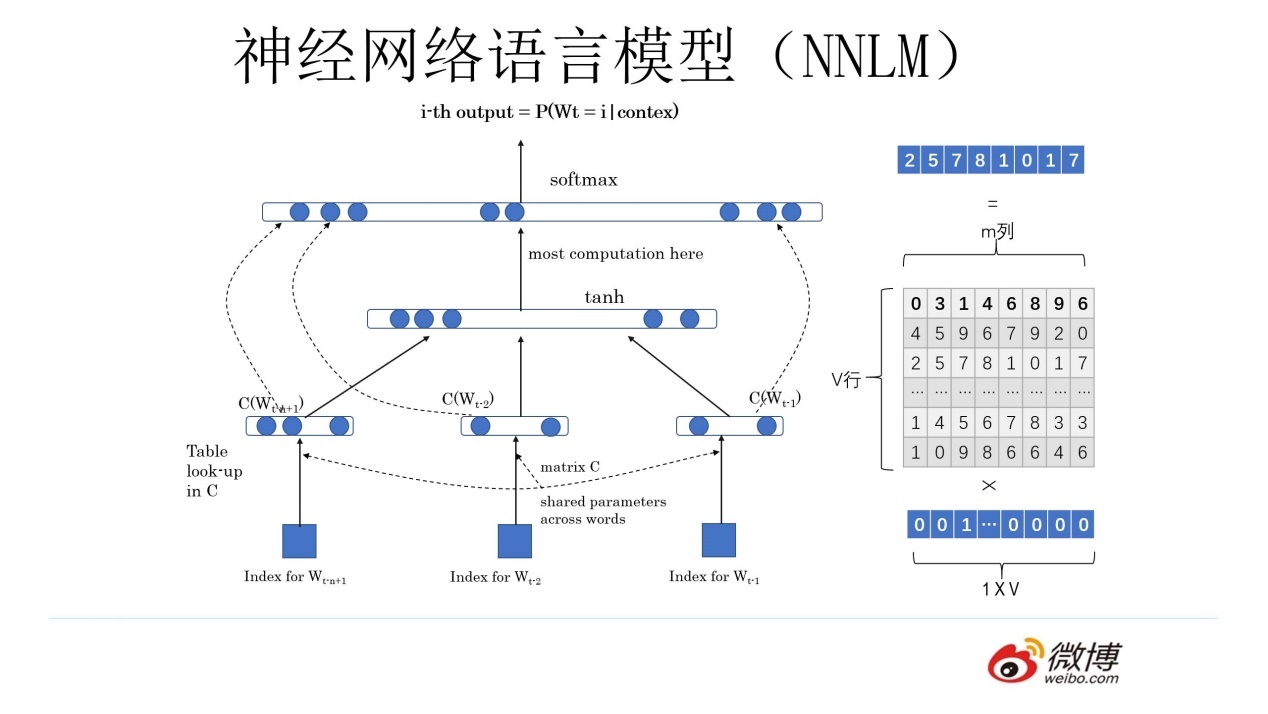 上图为神经网络语言模型结构图,它的学习任务是输入某个句中单词 wt=bertwt=bert 前的 t−1t−1 个单词,要求网络正确预测单词 “bert”,即最大化:
上图为神经网络语言模型结构图,它的学习任务是输入某个句中单词 wt=bertwt=bert 前的 t−1t−1 个单词,要求网络正确预测单词 “bert”,即最大化:
P(wt=bert|w1,w2,⋯,wt−1;θ)公式(7)P(wt=bert|w1,w2,⋯,wt−1;θ)公式(7)
上图所示的神经网络语言模型分为三层,接下来我们详细讲解这三层的作用:
神经网络语言模型的第一层,为输入层。首先将前 n−1n−1 个单词用 Onehot 编码(例如:0001000)作为原始单词输入,之后乘以一个随机初始化的矩阵 Q 后获得词向量 C(wi)C(wi),对这 n−1n−1 个词向量处理后得到输入 xx,记作 x=(C(w1),C(w2),⋯,C(wt−1))x=(C(w1),C(w2),⋯,C(wt−1))
神经网络语言模型的第二层,为隐层,包含 hh 个隐变量,HH 代表权重矩阵,因此隐层的输出为 Hx+dHx+d,其中 dd 为偏置项。并且在此之后使用 tanhtanh 作为激活函数。
神经网络语言模型的第三层,为输出层,一共有 |V||V| 个输出节点(字典大小),直观上讲,每个输出节点 yiyi 是词典中每一个单词概率值。最终得到的计算公式为:y=softmax(b+Wx+Utanh(d+Hx))y=softmax(b+Wx+Utanh(d+Hx)),其中 WW 是直接从输入层到输出层的权重矩阵,UU 是隐层到输出层的参数矩阵。
输入层
Onehot 编码:这是一种将单词转换成数值向量的方法,其中每个单词由一个很长的向量表示,向量中只有一个元素是1,其他都是0。这个1的位置对应于单词在词汇表中的位置。
词向量:Onehot 编码的向量会乘以一个随机初始化的矩阵 Q,这个矩阵的目的是将高维的 Onehot 向量映射到一个低维的空间,这个低维向量称为词向量 C(wi),它能够捕捉单词的语义信息。
输入 x:将前 n-1 个单词的词向量组合起来,形成输入层的一个向量 x,这个向量将作为隐层的输入。
隐层
隐变量:隐层包含 h 个隐变量,这些变量在训练过程中学习到如何表示输入数据的内在特征。
权重矩阵 H:隐层的输出是通过将输入向量 x 与权重矩阵 H 相乘,然后加上偏置项 d 来计算的。
激活函数 tanh:计算得到的隐层输出会通过双曲正切函数(tanh)进行非线性变换,这是为了引入非线性因素,使得模型能够学习更复杂的函数。
输出层
输出节点:输出层有 |V| 个节点,其中 |V| 是词汇表的大小。每个节点对应词汇表中的一个单词。
计算公式:输出层的计算涉及到三个部分:直接从输入层到输出层的权重矩阵 W,隐层到输出层的参数矩阵 U,以及偏置项 b 和 d。最终,输出层的计算结果是这三个部分组合后的结果,通过 softmax 函数进行归一化,得到每个单词的概率分布。
softmax 函数的作用是将输出层的原始得分转换为概率分布,这样每个输出节点的值就表示了给定上下文时词汇表中每个单词出现的概率。
总结一下,这个神经网络语言模型的工作流程是:
将单词序列转换为词向量。
通过隐层学习单词序列的内在表示。
通过输出层预测下一个单词的概率分布。
这个模型通过训练数据学习权重矩阵 Q、H、W 和 U,以及偏置项 b 和 d,从而能够在给定上下文的情况下预测下一个单词。