
MaXiaoTiao
微调(LoRA微调)
微调(LoRA微调)
什么是参数高效微调?固定大部分预训练模型(LLM)参数,微调少量或额外的模型参数。以往说的微调,一般指的是全量微调,就是所有的参数都来训练。为什么在大语言模型领域,很少人提全量微调,反而参数高效微调被提得更多呢?因为全量微调占用的显存太大了。以llama2-7B为例,不考虑中间激活,训练时将会占用至少140G显存。一张特斯拉V100的显卡的显存只有32G,不考虑中间激活层,就已经要占用5张显卡了。
LoRA的结构
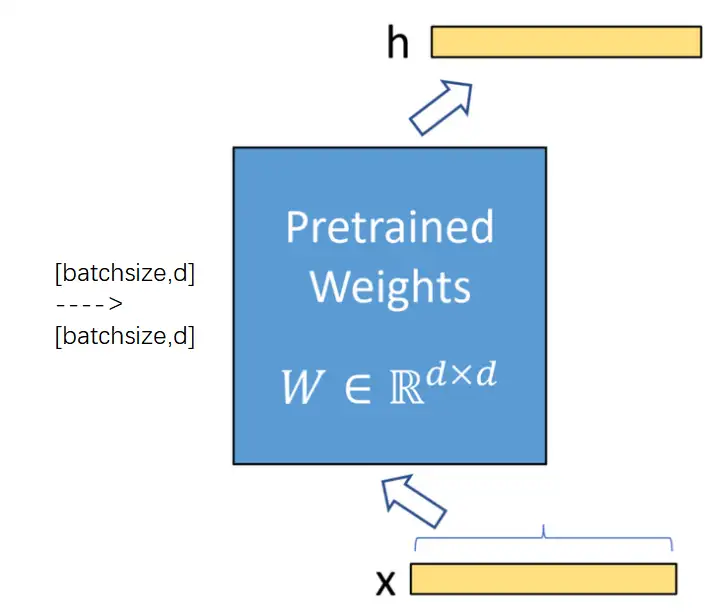
加入lora之前的模型结构
这张图是加入lora之前的模型结构,是一个很正常的全连接层。这个全连接层的参数矩阵的shape是d*d。一个shape=[batchsize,d]的输入,经过这个全连接层之后,得到shape=[batchsize,d]的输出。
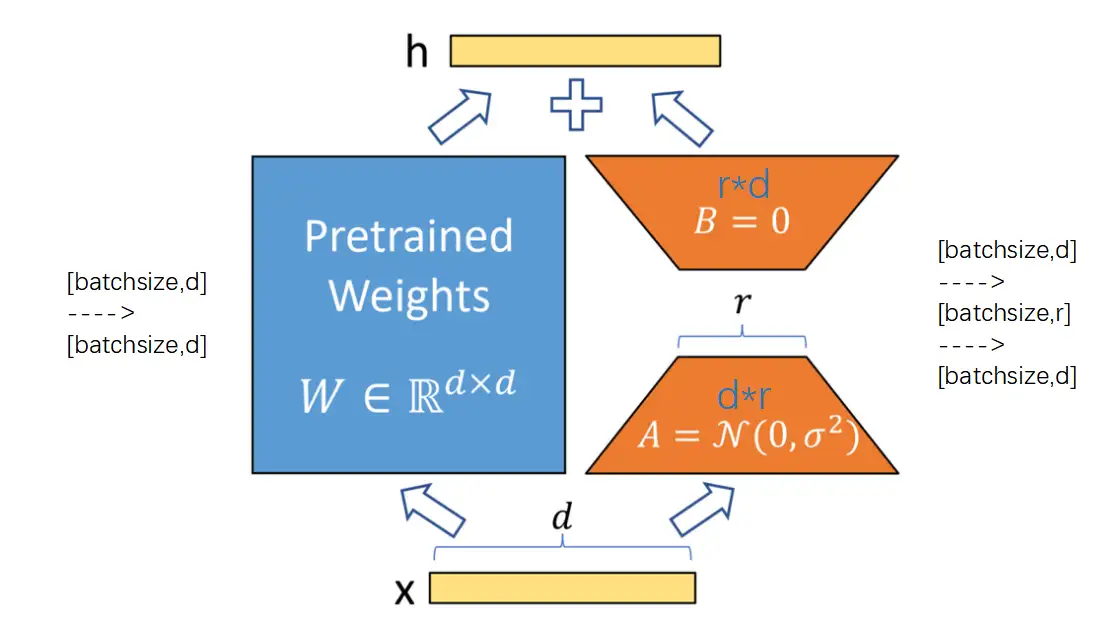
lora的结构
lora是加了一个旁路,相当于加了一个残差连接。这个旁路由两个参数矩阵组成,第一个是d*r的参数矩阵,第二个是r*d的参数矩阵。这就是刚刚说的结论,一个m*m的矩阵,可以用一个m*r的矩阵乘以一个r*n的矩阵来近似。也就是说,我们首先假设这个旁路的参数是一个d*d的矩阵,但是d*d太大了,需要降维,降维成一个d*r矩阵和一个r*d的矩阵。那么一个shape=[batchsize,d]的输入,经过d*r的矩阵后,得到[batchsize,r]的输出,然后再经过一个r*d的参数矩阵,得到[batchsize,d]的输出。最后和左边的主干加起来。
有一个细节是,r*d的矩阵的初始化,是全0初始化。全0意味着旁路的输出也是0。也就是说,模型初始化的时候,至少要保证加了lora的效果没有对原来主路的效果产生扰动。
简单实现
lora怎么实现呢?非常简单,已经有现成的库,就是peft库,借助这个库,实现lora就是几行代码的事情。我们先简单定义一个网络,这个网络是由两个linear层叠加的。注意在代码的输出处可以看到,第一个线性层的name是“0”。
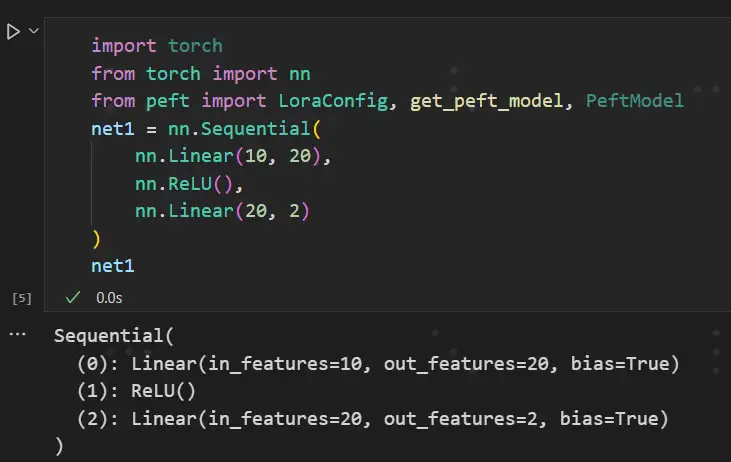
接下来,要在这个第0层的线性层注入一个lora,只需要加参数target_modules=['0'],代表给名字为0的层注入lora。接下来看看注入了lora后的model长什么样。
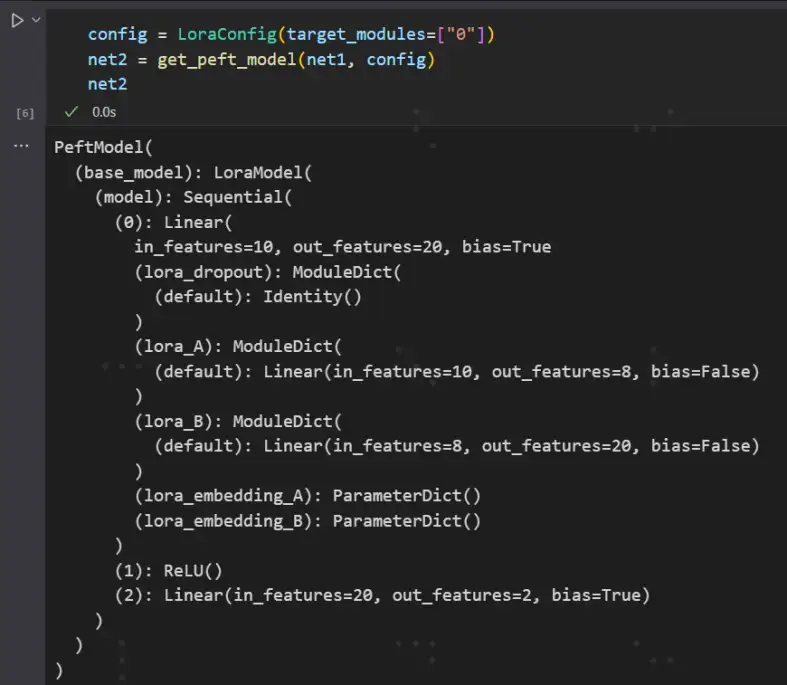
可以看到第0层多了两个线性层:lora_A和lora_B,第一个线性层的参数矩阵是10*8,这个8就是r,就是秩,我没有去手动指定,它默认是8。第二个线性层的参数矩阵是8*20。所以可以看到一个10*20的矩阵,用一个10*8和8*20的矩阵来近似了。
两个超参数
现在的库已经封装得特别好了,我们要做的只有两件事,就是把lora注入到哪里,以及秩要指定为多少。理论上有全连接层的地方都可以放。我们回顾transformer有哪些地方有全连接层呢?有七个地方。一开始的embedding层,每一个transformer层的Wq/Wk/Wv/Wo四个全连接层,每一个transformer层的前馈层包括两个全连接层。一般来说,注入到q和v的效果是最好的。比如在llama中,是将lora注入到所有自注意力层的q/v矩阵,在chatglm中,则是将lora注入到所有自注意力层的q/k/v矩阵。
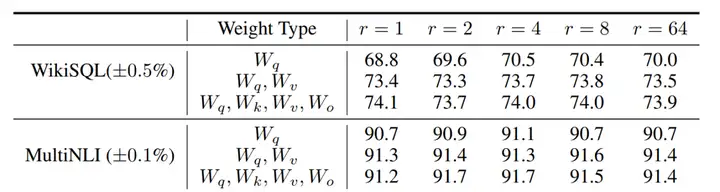
第二个可以选择的参数是秩的选择,可以看到在不同的指标下,r=4的效果相对来说是最好的。一般来说,r取4,8,12的性价比比较高。代码中我没有指定,默认r=8。
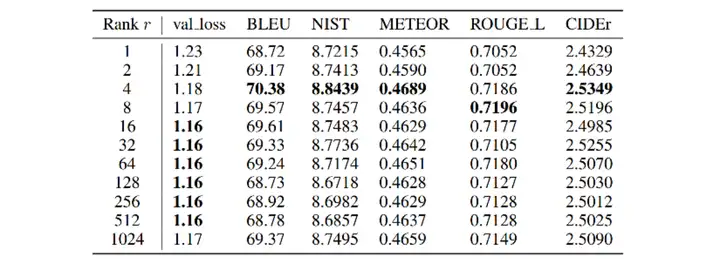
还有一些参数大家可以自己探究,比如lora_alpha,代表lora旁路的权重大小。
训练和推理
我跑了一遍训练和推理的步骤。以llama-7B为例,模型参数量6 738 415 616,(以fp16的形式)占用显存13761M。注入了lora之后,LoRA参数增量是4 194 304,参数占比只有0.00062。
接下来去训练,我用了一个几千条的指令微调数据集去做微调。seq_length设置的是340。
batchsize=1时显存增量是4172M, batchsize=2时显存增量是8798M, batchsize=3时显存增量是15494M,batchsize=4时,我的32G显存的V100罢工了。

至于推理的话,lora完全不会增加推理时间。我们看这个公式:
h=Wx+ΔWx=Wx+BAx=(W+BA)x
h其实相当于两个矩阵相加,即W+BA。训练好模型之后,可以把两条通路加在一起(把lora的通路去掉,把lora通路的参数加到主干即可)。合并在一起后的模型,参数量和计算量没有增加。
还能从另一个角度来理解这个公式: Wx+ΔWx 像不像参数更新的公式?lora可以理解为用低秩矩阵去近似下降的梯度。
LoRA的缺陷
我们知道,LoRA的核心假设是增量矩阵是低秩的。如果这个假设不满足呢?如果微调的数据量很大,实际的秩可能会很大,如果再强行压缩到rank=8,损失的信息会很多,这个时候不如全量微调。以LoRA为代表的PEFT本质是在计算资源受限的情况下的弥补方案,并不能起到代替主菜的作用。
上篇文章介绍了LoRA(武辰:【参数高效微调系列1】LoRA的原理与简单实战),今天简单介绍BitFit和IA3。LoRA、BitFit和IA3都是比较简单的参数高效微调方法。